linux基础服务管理
什么是服务,机器上运行的软件。
在学了linux基础命令后,下一步就是学习linux的各种服务配置,运维的日常,也就是使用linux命令作为基本功,去维护,操作各种服务配置,服务指的是各种应用程序。
java开发程序,如何吧java程序部署到服务器上,配置管理。
比如以后会接触的web服务、数据库服务等。nginx,mysql
但是我们先学习linux自带的一些应用程序,一个基础服务,是不需要你单独安装的,系统装好后,自带的服务,可以直接使用,来完成一些功能。那明显的,其他一些服务,就是需要我们额外安装的。
自有服务概述
服务是一些特定的进程,自有服务就是系统开机后就自动运行的一些进程,一旦客户发出请求,这些进程就自动为他们提供服务,windows系统中,把这些自动运行的进程,称为"服务"
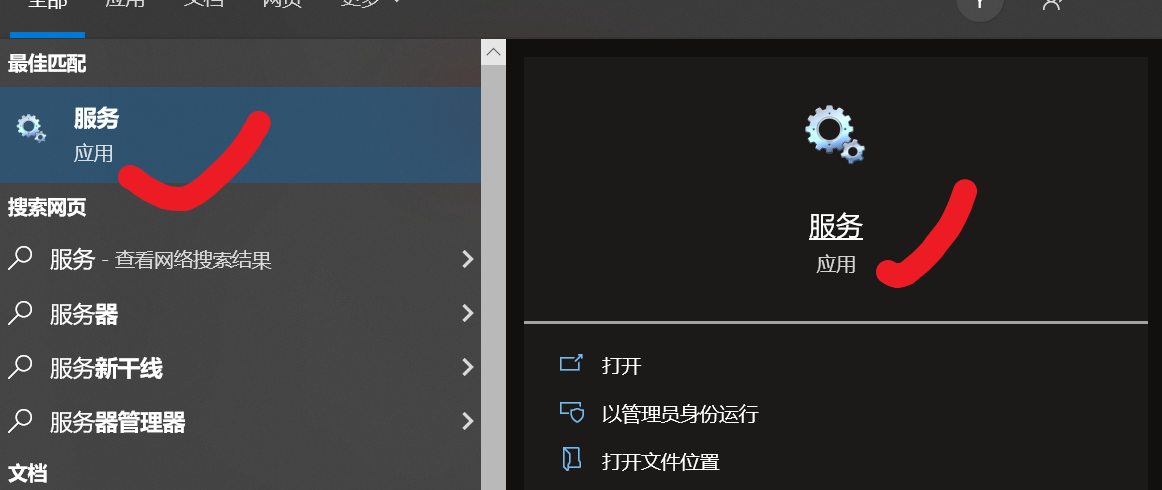
windows自带的各种服务
举例:当我们使用SSH客户端软件连接linux的时候,我们的服务器为什么会对连接做出响应?是因为SSH服务开机就自动运行了。
所谓自有服务,简单来说,可以理解为Linux系统开机自动运行的服务(程序)。
我们如何管理这些自有服务呢?
systemctl管理服务命令
service命令用于对系统服务进行管理,比如启动(start)、停止(stop)、重启(restart)、重新加载配置(reload)、查看状态(status)等。
在Ubuntu 22.04中,与CentOS 7之前使用service和chkconfig命令来管理服务的方式不同,Ubuntu使用systemctl命令来管理系统服务。这是因为Ubuntu 22.04使用了systemd作为其系统和服务管理器,而systemd是Linux系统中的一个系统和服务管理器,用于初始化系统资源、启动和管理系统服务。
基本systemctl命令:
启动服务
sudo systemctl start [服务名]停止服务
sudo systemctl stop [服务名]重启服务
sudo systemctl restart [服务名]显示服务状态
sudo systemctl status [服务名]在系统启动时启用服务
sudo systemctl enable [服务名]在系统启动时禁用服务
sudo systemctl disable [服务名]
systemctl与service和chkconfig的对比
systemctl:systemd的命令行工具,用于检查和控制系统和服务状态。service:在旧的SysVinit系统中用于启动、停止、重启和显示系统服务的状态的命令。在支持systemd的系统上,这个命令通常被链接到systemctl,允许使用旧的service命令语法来控制服务。chkconfig:在旧的SysVinit系统中用于启用或禁用系统服务的命令。在使用systemd的系统中,systemctl enable和systemctl disable提供了相同的功能。
Ubuntu 22.04偏好使用systemctl命令,因为它提供了更多的功能和对systemd服务的更好支持。通过使用systemctl,你可以更细粒度地控制系统服务,并利用systemd提供的高级功能,比如依赖性管理和服务单位文件的配置。
systemd是一个系统和服务管理器,它已成为多数Linux发行版的标准初始化系统(init系统),包括Ubuntu。systemd旨在提供比传统的SysV init系统更快的启动速度和更强大的管理能力。自Ubuntu 15.04(Vivid Vervet)起,systemd成为了Ubuntu的默认init系统。
systemd是什么
systemd是Linux操作系统中的一个初始化系统和系统管理器,负责启动系统后的所有其他程序,并管理系统级别的服务。它以系统服务的形式运行,为运行在Linux上的服务提供了启动、停止、重启、管理和查询的能力。systemd是为了提高系统的启动速度和管理的效率而设计的,它通过使用socket和D-Bus进行服务间的通信,以及为服务编写的单元文件(unit files)来实现这一目标。这些单元文件描述了服务的依赖关系、启动顺序和各种管理动作。
systemd的重要性
对于运维人员来说,理解systemd及其工作原理非常重要,原因包括:
- 系统管理和服务控制:
systemd取代了传统的SysVinit系统,提供了一种更加高效和可靠的方式来管理系统服务和进程。掌握systemd,运维人员可以更好地管理系统服务,例如启动、停止、重启服务,以及配置服务在系统启动时自动运行。 - 日志管理:通过
systemd-journald服务,systemd提供了强大的日志管理功能,使得跟踪和诊断系统问题变得更加容易。运维人员需要了解如何查询和管理这些日志来帮助故障排除。 - 系统状态和行为的配置:
systemd允许通过单元文件配置服务和其他系统资源的行为。了解如何编写和修改这些单元文件对于定制系统行为和确保服务正确运行非常重要。 - 性能和资源管理:
systemd提供了资源管理功能,比如通过systemd-cgtop和systemd-nspawn等工具,可以监控和限制资源使用(如CPU和内存)。这对于优化系统性能和资源利用至关重要。 - 安全性:
systemd还提供了一些安全特性,如通过systemd单元文件限制服务的权限,这有助于提升系统安全性。 - 兼容性和标准化:随着
systemd在多数主流Linux发行版中的采用,对systemd的了解保证了运维人员能够跨多个平台有效工作,实现知识和技能的可移植性。
结论
对于运维人员而言,深入理解systemd及其组件是非常必要的。它不仅有助于有效地管理和维护Linux系统,还能确保系统的稳定、安全和高效运行。systemd的学习和掌握是现代Linux系统管理的关键部分。
systemd主要特性包括
- 并行启动依赖服务:
systemd利用Linux内核的特性并行启动服务,减少系统启动时间。 - 服务依赖管理:
systemd通过服务单元文件(unit files)管理服务之间的依赖关系,确保服务按正确的顺序启动。 - 系统状态快照:
systemd可以创建系统状态的快照,并能够恢复到这些快照,便于系统管理和故障恢复。 - 日志管理(
systemd-journald):systemd引入了journald,一个新的日志系统,它集成了对所有系统日志和服务日志的收集、查询和管理。 - socket激活:服务可以通过socket激活延迟启动,直到有数据传入对应的socket,从而减少系统启动时的资源消耗。
- 定时器:
systemd提供了定时器功能,作为cron和at命令的替代品,允许计划任务在特定时间执行。
管理命令
systemd的主要命令是systemctl,用于管理系统和服务。通过systemctl,你可以启动、停止、重启、查看服务状态以及启用或禁用服务的自动启动等。
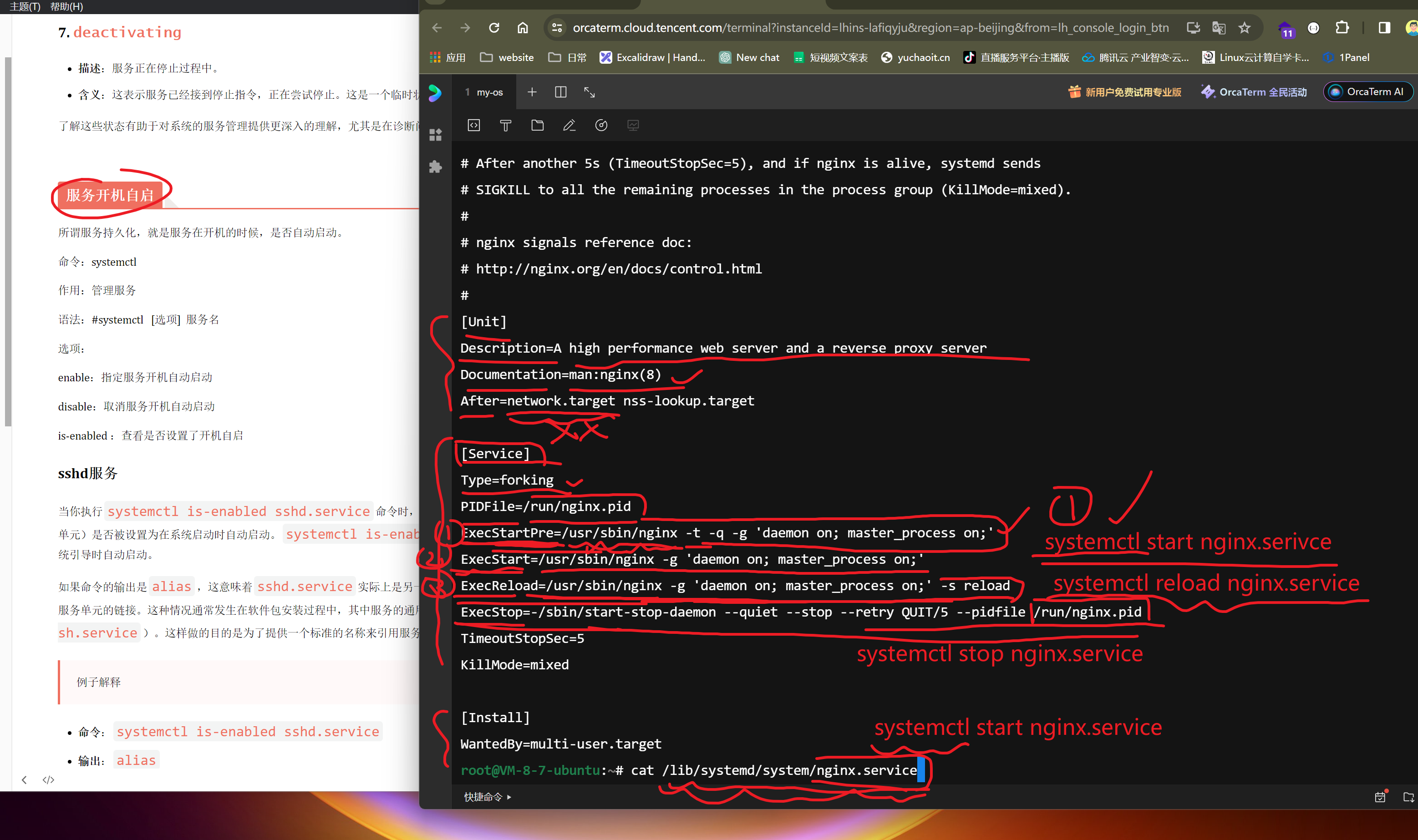
单元文件
systemd通过单元文件(Unit files)来管理资源。这些文件描述了一个服务、挂载点、设备、定时器或其他资源的配置。单元文件通常位于/etc/systemd/system/(系统特定的单元)或/usr/lib/systemd/system/(软件包提供的单元)目录下。通过编辑单元文件,管理员可以精确控制服务的行为。
systemd的目标
systemd使用"目标"(targets)来代表系统的运行级别。这些目标替代了传统SysV init系统中的运行级别(runlevels),提供了更灵活的启动过程配置方式。例如,multi-user.target相当于传统的运行级别3,而graphical.target则相当于运行级别5。
systemd对系统管理的影响
systemd通过其高级特性和管理工具,为系统管理员提供了强大的系统控制能力。它不仅提高了系统启动速度,还简化了服务管理和系统配置的过程。虽然systemd的引入在Linux社区内引发了一定的争议,但它的设计哲学和管理能力已被许多主流Linux发行版采纳。
systemd进程
root@VM-8-7-ubuntu:~# ps -ef |grep systemd
root 356 1 0 Feb27 ? 00:02:07 /lib/systemd/systemd-journald
root 403 1 0 Feb27 ? 00:00:02 /lib/systemd/systemd-udevd
systemd+ 734 1 0 Feb27 ? 00:00:01 /lib/systemd/systemd-networkd
systemd+ 736 1 0 Feb27 ? 00:00:32 /lib/systemd/systemd-resolved
message+ 754 1 0 Feb27 ? 00:00:19 @dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only
root 778 1 0 Feb27 ? 00:00:06 /lib/systemd/systemd-logind
systemd+ 745590 745523 0 Feb29 pts/0 00:00:00 nginx: worker process
ubuntu 1013410 1 0 14:45 ? 00:00:00 /lib/systemd/systemd --user
root 1014300 1014086 0 14:48 pts/2 00:00:00 grep --color=auto systemd
root@VM-8-7-ubuntu:~#
systemctl命令
systemctl(英文全拼:system control)用于控制 systemd 系统和管理服务。
语法
systemctl [OPTIONS...] COMMAND [UNIT...]
command 选项字如下:
start:启动指定的 unit。
stop:关闭指定的 unit。
restart:重启指定 unit。
reload:重载指定 unit。
enable:系统开机时自动启动指定 unit,前提是配置文件中有相关配置。
disable:开机时不自动运行指定 unit。
status:查看指定 unit 当前运行状态。
参数:unit 是要配置的服务名称。
| 任务 | 旧指令 | 新指令 |
|---|---|---|
| 使某服务自动启动 | chkconfig --level 3 httpd on | systemctl enable httpd.service |
| 使某服务不自动启动 | chkconfig --level 3 httpd off | systemctl disable httpd.service |
| 检查服务状态 | service httpd status | systemctl status httpd.service (服务详细信息) systemctl is-enabled httpd.service (仅显示是否 Active) |
| 显示所有已启动的服务 | chkconfig --list | systemctl list-units --type=service |
| 启动某服务 | service httpd start | systemctl start httpd.service |
| 停止某服务 | service httpd stop | systemctl stop httpd.service |
| 重启某服务 | service httpd restart | systemctl restart httpd.service |
| 某服务重新加载配置文件 | service httpd reload | systemctl reload httpd.service |
所有的systemctl命令,忘记用法的话,最直接的方式,看帮助手册。
[root@yuchao-linux01 ~]# systemctl --help
显示服务
命令:systemctl
作用:管理服务
语法:#systemctl [选项]
选项:
list-units --type service --all:列出所有服务(包含启动的和没启动的)
list-units --type service:列出所有启动的服务
区别就在于--all参数
实践
显示出系统中所有的服务,默认管理的应用程序有哪些
和windows打开服务功能一样。
包括在运行的,以及未运行的服务
空格翻页,q退出查看
root@VM-8-7-ubuntu:~# systemctl list-units --type service --all |head
UNIT LOAD ACTIVE SUB DESCRIPTION
1panel.service loaded active running 1Panel, a modern open source linux panel
acpid.service loaded active running ACPI event daemon
apparmor.service loaded active exited Load AppArmor profiles
apport-autoreport.service loaded inactive dead Process error reports when automatic reporting is enabled
apport.service loaded active exited LSB: automatic crash report generation
apt-daily-upgrade.service loaded inactive dead Daily apt upgrade and clean activities
apt-daily.service loaded inactive dead Daily apt download activities
● auditd.service not-found inactive dead auditd.service
blk-availability.service loaded active exited Availability of block devices
root@VM-8-7-ubuntu:~#
在这个输出中,我们看到了systemctl list-units --type service --all | head命令的结果。这条命令列出了系统上所有服务单位(unit)的状态,通过head命令我们只看到了前几行。让我们逐项解释输出的各部分:
- UNIT:这是服务的名称,后缀为
.service,代表这是一个服务单位。 - LOAD:指明了服务的加载状态,
loaded表示服务已经被加载到系统中;not-found表示没有找到服务的定义文件。 - ACTIVE:显示服务的活动状态。
active表示服务正在运行;inactive表示服务未运行;exited表示服务已执行完成其任务然后退出。 - SUB:是服务的子状态,提供了关于服务状态的更多细节。例如,
running表示服务当前正在运行;exited表示服务已完成启动过程并退出(通常用于一次性服务);dead表示服务未运行。 - DESCRIPTION:对服务的简短描述。
下面是对列出的几个服务的简单说明:
- 1panel.service:一种现代开源Linux面板,处于加载并运行状态。
- acpid.service:ACPI事件守护进程,负责处理电源按钮和其他ACPI事件,已加载并处于运行状态。
- apparmor.service:加载AppArmor安全模块的服务,已加载并已完成其任务。
- apport-autoreport.service:当自动报告启用时处理错误报告的服务,目前没有运行。
- apport.service:自动崩溃报告生成的服务,已加载并已完成其任务。
- apt-daily-upgrade.service 和 apt-daily.service:负责每日的APT更新和升级的服务,目前没有运行。
- auditd.service:这是系统审计守护进程的服务,但在这个系统上没有找到相应的服务文件。
- blk-availability.service:检查块设备可用性的服务,已加载并已完成其任务。
这个命令的输出帮助系统管理员快速了解系统上各服务的状态,进而进行相应的管理和调整。
查看服务运行状态
命令:systemctl
作用:管理服务
语法:#systemctl [选项] 服务名
选项:
status:检查指定服务的运行状况
start:启动指定服务
stop:停止指定服务
restart:重启指定服务
reload:重新加载指定服务的配置文件(并非所有服务都支持reload,通常使用restart)
root@VM-8-7-ubuntu:~# systemctl status sshd
● ssh.service - OpenBSD Secure Shell server
Loaded: loaded (/lib/systemd/system/ssh.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2024-02-27 19:57:07 CST; 1 week 5 days ago
Docs: man:sshd(8)
man:sshd_config(5)
Main PID: 849 (sshd)
Tasks: 1 (limit: 3943)
Memory: 23.0M
CPU: 18min 28.902s
CGroup: /system.slice/ssh.service
└─849 "sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups"
Mar 11 14:45:55 VM-8-7-ubuntu sshd[1013479]: Accepted password for ubuntu from 39.144.92.210 port 3848 ssh2
Mar 11 14:45:55 VM-8-7-ubuntu sshd[1013479]: pam_unix(sshd:session): session opened for user ubuntu(uid=1000) by (uid=0)
Mar 11 14:52:17 VM-8-7-ubuntu sshd[1015372]: Invalid user dasan from 146.190.30.118 port 56564
Mar 11 14:52:17 VM-8-7-ubuntu sshd[1015372]: pam_unix(sshd:auth): check pass; user unknown
Mar 11 14:52:17 VM-8-7-ubuntu sshd[1015372]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rh>
Mar 11 14:52:19 VM-8-7-ubuntu sshd[1015372]: Failed password for invalid user dasan from 146.190.30.118 port 56564 ssh2
Mar 11 14:52:21 VM-8-7-ubuntu sshd[1015372]: Connection closed by invalid user dasan 146.190.30.118 port 56564 [preauth]
Mar 11 14:53:59 VM-8-7-ubuntu sshd[1015837]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rh>
Mar 11 14:54:01 VM-8-7-ubuntu sshd[1015837]: Failed password for root from 68.183.190.166 port 35564 ssh2
Mar 11 14:54:01 VM-8-7-ubuntu sshd[1015837]: Connection closed by authenticating user root 68.183.190.166 port 35564 [preauth]
lines 1-22/22 (END)
服务运行结果
在systemd中,服务的状态是用来描述服务当前运行状况的关键指标。状态信息显示在systemctl status命令的输出中,或者可以通过其他systemctl命令查询得到。一个服务的Active状态描述了该服务是否正在运行,以及运行的方式。下面是systemd服务的Active状态中可能出现的几种状态及其含义:
1. active (running)
- 描述:服务当前正在运行。
- 含义:这表示服务已成功启动并且正在执行其主要功能。对于后台服务,这意味着它已经在后台运行;对于一次性服务,这可能表示服务正在执行某些任务。
2. active (exited)
- 描述:服务已启动并完成了其任务,目前没有运行任何进程。
- 含义:这通常用于那些启动时执行配置或设置任务然后退出的服务。尽管这些服务当前没有运行进程,它们仍被视为已激活,因为它们已成功完成了它们的启动任务。
3. active (waiting)
- 描述:服务已启动,但正在等待某个条件或事件。
- 含义:这种状态常见于等待另一个服务、网络连接、设备挂载或任何其他条件的服务。服务处于激活状态,但其执行可能取决于外部条件的满足。
4. inactive (dead)
- 描述:服务未启动。
- 含义:这表示服务当前没有运行。服务可能从未启动,或者已经被停止。这是服务默认的初始状态。
5. failed
- 描述:服务尝试启动但失败了。
- 含义:这表明服务在启动过程中遇到了错误,无法达到激活状态。通常,需要检查服务的日志文件来了解失败的原因。
6. activating
- 描述:服务正在启动过程中。
- 含义:这表示服务已经接到启动指令,正在尝试启动。这是一个临时状态,服务将会转移到
active、inactive或failed状态。
7. deactivating
- 描述:服务正在停止过程中。
- 含义:这表示服务已经接到停止指令,正在尝试停止。这是一个临时状态,最终服务将转移到
inactive或failed状态。
了解这些状态有助于对系统的服务管理提供更深入的理解,尤其是在诊断问题和配置服务行为时。
服务开机自启
所谓服务持久化,就是服务在开机的时候,是否自动启动。
命令:systemctl
作用:管理服务
语法:#systemctl [选项] 服务名
选项:
enable:指定服务开机自动启动
disable:取消服务开机自动启动
is-enabled :查看是否设置了开机自启
sshd服务
当你执行systemctl is-enabled sshd.service命令时,这个命令检查的是sshd.service(SSH守护进程的服务单元)是否被设置为在系统启动时自动启动。systemctl is-enabled命令用于查询服务的启用状态,这决定了服务是否在系统引导时自动启动。
如果命令的输出是alias,这意味着sshd.service实际上是另一个服务单元的别名。在systemd中,"别名"是指向另一个服务单元的链接。这种情况通常发生在软件包安装过程中,其中服务的通用名称(如sshd)被链接到特定于发行版的服务文件(如ssh.service)。这样做的目的是为了提供一个标准的名称来引用服务,不论底层使用的实际单元文件是什么。
例子解释
- 命令:
systemctl is-enabled sshd.service - 输出:
alias
这表示sshd.service实际上是作为另一个服务单元的别名启用的。要找出sshd.service是哪个服务的别名,你可以查看sshd.service文件的实际路径(通常通过ls -l命令查看符号链接),或者查看系统的systemd配置来确定它指向的实际服务单元文件。
如何解决或进一步操作
要进一步了解sshd.service的配置和状态,你可以直接查询它的目标(实际的服务单元),例如:
systemctl status ssh.service
root@VM-8-7-ubuntu:~# systemctl is-enabled ssh
enabled
这假设sshd.service是ssh.service的别名。替换为实际的目标服务名称,如果它与ssh.service不同。这将给你提供关于SSH服务状态、是否启动、是否遇到错误等详细信息。
时间服务,管理时间同步的程序
ntp时间同步服务
NTP是网络时间协议(Network Time Protocol),它是用来同步网络中各个计算机的时间的协议。
在计算机的世界里,时间非常地重要
例如:对于火箭发射这种科研活动,对时间的统一性和准确性要求就非常地高,是按照A这台计算机的时间,还是按照B这台计算机的时间?
NTP就是用来解决这个问题的,NTP(Network Time Protocol,网络时间协议)是用来使网络中的各个计算机时间同步的一种协议。
它的用途是把计算机的时钟同步到世界协调时UTC,其精度在局域网内可达0.1ms,在互联网上绝大多数的地方其精度可以达到1-50ms。
服务器时间很重要
公司开发了一个电商网站,由于访问量很大,网站后端由100台服务器组成集群。
50台负责接收订单,50台负责安排发货,接收订单的服务器需要记录用户下订单的具体时间,把数据传给负责发货的服务器,由于100台服务器时间各不相同,记录的时间经常不一致,甚至会出现下单时间是明天,发货时间是昨天的情况。
时间是很重要的一个单位概念,很多新手、老手,都可能在时间同步服务上翻车,很多服务部署,因为时间的不同步,都会导致出错,增加排错难度。
特别是在集群下,多台服务器,需要部署联调,由于时间不正确,可能导致通信异常。
需要时间的应用。
定时任务的执行
数据同步,时间不一致等。
因此保证服务器之间的时间一致,非常重要。
ntpd是NTP协议的旧版实现,而chrony被设计为更现代和高效的时间同步工具,尤其适合动态IP地址的环境和系统从睡眠中醒来的情况。
如果你需要更高级的时间同步功能,例如更精确的时钟控制或者更复杂的网络环境支持,可能会考虑安装chrony或ntpd。
标准时间来自哪
标准时间是哪里来的?
现在的标准时间是由原子钟报时的国际标准时间UTC(Universal Time Coordinated,世界协调时),所以NTP获得UTC的时间来源可以是原子钟、天文台、卫星,也可以从Internet上获取。
在NTP中,定义了时间按照服务器的等级传播,Stratum层的总数限制在15以内
工作中,通常我们会直接使用各个组织提供的,现成的NTP服务器。
NTP授时网站:http://www.ntp.org.cn/pool
timedatectl命令
timedatectl和chronyd服务两者在Linux系统中用于处理与时间相关的不同方面,但它们的作用和用途有所不同。它们之间的主要区别在于它们各自的职责范围和工作方式。
timedatectl
timedatectl是systemd的一部分,提供了一个命令行接口,用于查看和更改系统的时间和日期设置。- 它允许用户查询和更改系统时钟(RTC)的设置,包括时间、日期、时区以及是否启用NTP(网络时间协议)同步。
timedatectl可以用来启用或禁用systemd-timesyncd服务(一个简单的NTP客户端),但它本身不执行时间同步操作。- 通过
timedatectl,用户可以方便地管理和查看系统的时间相关配置,而无需直接与底层时间同步服务交互。
chronyd
chronyd是chrony软件包提供的守护进程,负责与NTP服务器通信,同步系统时钟。chronyd设计用来在各种网络条件下高效同步时间,特别适合处理网络延迟变化大或系统从睡眠状态唤醒时的快速同步。- 它通过复杂的算法调整本地时钟速率,以精确跟踪真实世界的时间。
chronyd的配置和管理通常通过编辑其配置文件(如/etc/chrony/chrony.conf)和使用特定的命令(如chronyc,chrony的命令行接口)来进行。
关系和用途
- 虽然
timedatectl可以用来启用或禁用NTP同步,但当选择使用chronyd作为时间同步服务时,chronyd将独立于timedatectl操作。此时,timedatectl仍然可以用来查看系统时间设置,但实际的时间同步任务是由chronyd负责的。 - 使用
timedatectl status命令,你可以查看系统时间配置的概述,包括当前的时区和是否启用了NTP同步。如果系统使用chronyd,则NTP同步部分可能显示为活动状态,表明系统正在使用某种形式的NTP服务进行时间同步,而具体的同步任务则由chronyd执行。
简而言之,timedatectl是一个用于管理和查看系统时间配置的工具,而chronyd是执行时间同步的后台服务。两者在系统中共存,各自承担不同的职责。
root@VM-8-7-ubuntu:~# timedatectl
Local time: Mon 2024-03-11 15:33:07 CST
Universal time: Mon 2024-03-11 07:33:07 UTC
RTC time: Mon 2024-03-11 07:33:07
Time zone: Asia/Shanghai (CST, +0800)
System clock synchronized: yes
NTP service: n/a
RTC in local TZ: no
这是Linux系统中使用timedatectl命令查看系统时间和时区信息的输出。具体解释如下:
Local time: 本地时间,即当前系统的本地时间为2024年3月11日(星期一)15时33分07秒,使用了CST(China Standard Time,中国标准时间,UTC+8)时区。Universal time: 协调世界时(UTC),当前系统的UTC时间为2024年3月11日(星期一)07时33分07秒。RTC time: RTC(Real-Time Clock,实时时钟)时间,与UTC时间相同,都是2024年3月11日(星期一)07时33分07秒。Time zone: 时区,系统当前设置的时区为亚洲/上海(Asia/Shanghai),使用了CST时区,偏移量为+0800,即UTC+8。System clock synchronized: 系统时钟同步,显示系统时钟是否已经与网络时间协议(NTP)服务器同步。这里显示为"yes",表示系统时钟已经同步。NTP service: NTP服务,显示NTP服务的状态,这里显示为"n/a"(不适用),表示当前系统没有配置使用NTP服务。RTC in local TZ: RTC是否使用本地时区,显示RTC是否以本地时区的方式运行。这里显示为"no",表示RTC与本地时区无关联。
更新系统时间,强制同步
注意,这个操作,生产下不要随便更换时间,别碰就对了,公司会有内部的ntp时间服务器,或者和老大明确你的操作是否合规。
手动同步时间:您可以手动设置系统时间来与您期望的时间保持一致。使用
date命令可以手动设置系统时间,例如:sudo date MMDDhhmm[[CC]YY][.ss]其中MM为月份,DD为日期,hh为小时,mm为分钟,CC为世纪,YY为年份,ss为秒。
使用NTP客户端工具:除了
timedatectl之外,还可以使用其他NTP客户端工具来同步时间。例如,可以安装ntp软件包,并手动运行ntpdate命令来强制同步时间:sudo apt install ntpdate sudo ntpdate -u ntp.aliyun.com这将强制将系统时间设置为NIST(National Institute of Standards and Technology)时间服务器的时间。
错误解决
root@VM-8-7-ubuntu:~# ntpdate ntp.aliyun.com
11 Mar 15:40:16 ntpdate[1029771]: the NTP socket is in use, exiting
这个错误消息表示ntpdate命令无法执行同步,因为NTP套接字已被其他程序使用。这可能是因为已经有一个NTP客户端或服务正在运行,例如systemd-timesyncd或chrony。在这种情况下,您可以尝试使用其他工具或方法来同步时间,或者停止正在运行的NTP服务。
如果您确定没有其他NTP客户端或服务在运行,但仍然遇到此问题,请尝试重新启动系统并再次运行ntpdate命令。如果问题仍然存在,请检查系统日志以查看是否有关于NTP套接字被占用的其他详细信息。
# 解决过程
root@VM-8-7-ubuntu:~# ps -ef |grep ntp
ntp 7793 1 0 Feb27 ? 00:00:38 /usr/sbin/ntpd -p /var/run/ntpd.pid -g -u 113:118
root 1029998 1027409 0 15:41 pts/4 00:00:00 grep --color=auto ntp
发现ntp服务运行中,不让你手工同步。
# 停止ntpd服务
root@VM-8-7-ubuntu:~# systemctl stop ntp
root@VM-8-7-ubuntu:~#
root@VM-8-7-ubuntu:~# !ps
ps -ef |grep ntp
root 1030208 1027409 0 15:41 pts/4 00:00:00 grep --color=auto ntp
root@VM-8-7-ubuntu:~#
# 手工更新
root@VM-8-7-ubuntu:~# ntpdate ntp.aliyun.com
11 Mar 15:42:04 ntpdate[1030267]: adjust time server 203.107.6.88 offset +0.000155 sec
root@VM-8-7-ubuntu:~#
root@VM-8-7-ubuntu:~# timedatectl
Local time: Mon 2024-03-11 15:42:11 CST
Universal time: Mon 2024-03-11 07:42:11 UTC
RTC time: Mon 2024-03-11 07:42:11
Time zone: Asia/Shanghai (CST, +0800)
System clock synchronized: yes
NTP service: n/a
RTC in local TZ: no
root@VM-8-7-ubuntu:~#
查看ntp时间同步状态
要查看NTP同步状态,您可以使用ntpq命令。这个命令通常用于查询和调试NTP服务器。您可以按照以下步骤在Ubuntu上查看NTP同步状态:
sudo apt update
sudo apt install ntp
使用ntpq命令查看NTP服务器状态:
root@VM-8-7-ubuntu:~# ntpq -p
ntpq: read: Connection refused
root@VM-8-7-ubuntu:~#
必须要运行ntpd服务
# 查看配置
server time1.tencentyun.com iburst
server time2.tencentyun.com iburst
server time3.tencentyun.com iburst
server time4.tencentyun.com iburst
server time5.tencentyun.com iburst
interface ignore wildcard
interface listen eth0
这个/etc/ntp.conf配置文件指定了五个腾讯云NTP服务器作为时间服务器,并设置了NTP客户端的接口配置。
server time1.tencentyun.com iburst:指定了腾讯云的第一个NTP服务器作为时间服务器,并使用iburst选项,在启动时快速进行时间同步。
interface ignore wildcard:忽略所有接口的通配符(wildcard),这意味着NTP服务器将不会尝试通过任何接口进行广播或多播。
interface listen eth0:指定NTP服务器应该监听的网络接口为eth0,这意味着NTP服务器将只接受来自eth0接口的NTP请求。
这个配置文件将NTP客户端配置为使用腾讯云的五个NTP服务器之一,并且限制了NTP服务器的网络接口,使其只能监听eth0接口。这种配置适用于需要特定NTP服务器和接口配置的场景。
# 启动ntp
root@VM-8-7-ubuntu:~# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
169.254.0.79 9.11.174.246 2 u 31 64 1 0.499 +0.124 0.013
169.254.0.80 9.11.174.246 2 u 34 64 1 2.277 -1.093 0.005
169.254.0.81 9.20.184.92 2 u 31 64 1 6.793 -0.248 0.008
169.254.0.82 9.11.174.246 2 u 32 64 1 7.689 +0.310 0.005
*169.254.0.83 9.11.174.246 2 u 34 64 1 2.049 -0.157 0.007
这里显示了通过ntpq -p命令查询的NTP服务器同步状态。以下是输出中各列的含义:
remote:远程NTP服务器的IP地址或域名。refid:参考时钟的标识符。通常是一个IP地址或特定的时钟源。st:远程服务器的时钟层级(stratum)。较低的数字表示更接近于主时钟源。t:服务器的时钟类型。u表示未确定。when:从上次成功请求以来的时间(以秒为单位)。poll:NTP客户端向服务器发送请求的间隔(以秒为单位)。reach:显示NTP客户端自上次启动以来成功与服务器通信的次数。delay:客户端与服务器之间的网络延迟(以毫秒为单位)。offset:客户端时钟与服务器时钟之间的偏移量(以毫秒为单位)。正值表示客户端时钟快于服务器时钟。jitter:时钟偏移的变化率,用于估计时钟的稳定性。
在输出中,前面带有星号(*)的行表示NTP客户端当前正在使用的服务器。根据您的输出,您的NTP客户端当前正在使用169.254.0.83作为时间同步服务器,它的时钟偏移量(offset)为负值,表示客户端时钟比服务器时钟快。
ntpd配置文件
/etc/ntp.conf是NTP(Network Time Protocol,网络时间协议)的配置文件,在Linux系统中用于配置NTP服务器和客户端的行为。以下是该文件的一些常见配置选项和其含义的解释:
server:指定NTP服务器的地址或域名。可以指定多个服务器,每行一个。例如:server ntp1.example.com server ntp2.example.comrestrict:限制对NTP服务器的访问权限。可以用来限制哪些IP地址或网络可以访问NTP服务器,以及以何种方式访问。例如:restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap这个例子限制了192.168.1.0/24 网段的主机只能查询 NTP 服务器,不能修改或传送控制命令。
driftfile:指定NTP服务器的时钟漂移文件的路径。NTP服务器使用这个文件来保存时钟漂移量的估计值,以便在重新启动后恢复。例如:driftfile /var/lib/ntp/ntp.driftlogfile:指定日志文件的路径,用于记录NTP服务器的日志信息。例如:logfile /var/log/ntp.logpool:从NTP服务器池中获取时间同步信息。可以指定一个或多个NTP服务器池。例如:pool 0.ubuntu.pool.ntp.org iburst pool 1.ubuntu.pool.ntp.org iburst pool 2.ubuntu.pool.ntp.org iburst pool 3.ubuntu.pool.ntp.org iburstiburst选项表示在启动时快速进行时间同步。broadcastclient:启用广播客户端模式,允许服务器以广播方式发送时间信息,并通过广播接收时间信息。例如:broadcastclient
这些只是/etc/ntp.conf文件中的一些常见配置选项。根据您的需求和网络环境,可能还有其他配置选项可用。修改/etc/ntp.conf后,需要重新启动NTP服务才能使更改生效。
ntpstat状态
ntpstat命令用于显示本地NTP(Network Time Protocol)客户端的同步状态。它提供了关于NTP同步性能的简要信息。以下是ntpstat命令输出的一些常见含义:
synchronized:表示本地时钟与NTP服务器已经同步。time server:显示当前正在使用的NTP服务器的IP地址或域名。stratum:显示NTP服务器的时钟层级,数字越低表示层级越高。polling server every:显示NTP客户端向服务器发送同步请求的间隔。offset:显示本地时钟与NTP服务器时钟之间的偏移量,单位为毫秒。正值表示本地时钟比服务器时钟快,负值表示本地时钟比服务器时钟慢。precision:显示本地时钟的精度,以2的幂次方秒为单位。t:显示NTP客户端与服务器的最后一次通信的状态。-表示通信失败,+表示通信成功,*表示本地时钟与服务器同步。
例如,输出中的unsynchronised表示本地时钟未与NTP服务器同步,poll字段显示了NTP客户端向服务器发送同步请求的间隔,offset字段显示了本地时钟与服务器时钟之间的偏移量。
root@yuchao-linux-2024:~# apt install ntpstat -y
root@yuchao-linux-2024:~# ntpstat
synchronised to NTP server (169.254.0.79) at stratum 3
time correct to within 48 ms
polling server every 128 s
这里显示了ntpstat命令的输出:
synchronised to NTP server (169.254.0.79) at stratum 3:表示本地时钟已与NTP服务器(IP地址为169.254.0.79)同步,该服务器处于第3层级(stratum 3),即它的时钟源是通过第二级(stratum 2)的NTP服务器同步的。time correct to within 48 ms:表示本地时钟与NTP服务器的时间偏差在48毫秒以内,即本地时钟与NTP服务器的时间保持相对准确。polling server every 128 s:表示NTP客户端将每128秒向服务器发送一次同步请求,以确保本地时钟与服务器的同步性。
这个输出表明您的系统正在与NTP服务器同步时间,并且时间偏差在可接受范围内。
chronyd服务
chronyd是chrony软件包的主要守护进程,负责同步系统时钟与网络时间协议(NTP)服务器或其他时间源。chrony被设计来快速准确地同步系统时钟,即使在具有变化网络条件的环境中,也能有效地维持时间的精确度。
它特别适用于系统经常进入睡眠状态或者网络连接不稳定的情况,比传统的NTP客户端(如ntpd)在处理这些情况时更为高效。
chronyd的关键特性包括:
- 快速同步:
chronyd能够在系统启动时快速同步时钟,尤其是对于时钟严重偏差的情况。 - 高精度:
chronyd使用复杂的算法来调整时钟速率,使得系统时钟能够非常精确地跟踪真实世界的时间。 - 低资源消耗:
chronyd设计为消耗较少的系统资源,使得它适合在各种大小的系统上运行,包括嵌入式设备。 - 网络条件适应性:
chronyd可以适应网络延迟的变化,即使在网络条件不佳的情况下也能保持时间同步的准确性。 - 处理系统睡眠和唤醒:
chronyd能够在系统从睡眠或待机模式唤醒后迅速重新同步时间。 - 支持多种时间源:除了NTP服务器,
chronyd还支持其他时间源,包括手动设置的参考时钟、GPS接收器等。
配置和使用chronyd
- 安装:在大多数Linux发行版上,
chrony可以通过系统的包管理器安装。在Ubuntu上,使用sudo apt install chrony。 - 配置:
chrony的配置文件通常位于/etc/chrony/chrony.conf。在这个文件中,你可以指定NTP服务器、调整同步参数等。 - 管理服务:通过
systemctl命令管理chronyd服务,如启动(systemctl start chronyd)、停止(systemctl stop chronyd)、重启(systemctl restart chronyd)以及查看状态(systemctl status chronyd)。
chronyd提供了一种高效且灵活的方式来确保系统时钟的精确性和一致性,对于需要高精度时间同步的应用场景,如服务器、网络设备以及对时间敏感的应用,chronyd是一个优秀的选择。
禁用ntp,采用chronyd
sudo systemctl stop ntp
sudo systemctl disable ntp
sudo apt update
sudo apt install chrony -y
sudo systemctl enable chrony
sudo systemctl start chrony
root@yuchao-linux-2024:~# ps -ef |grep -E 'ntp|chrony'
_chrony 1046843 1 0 16:35 ? 00:00:00 /usr/sbin/chronyd -F 1
_chrony 1046844 1046843 0 16:35 ? 00:00:00 /usr/sbin/chronyd -F 1
root 1047205 1045712 0 16:36 pts/8 00:00:00 grep --color=auto -E ntp|chrony
root@yuchao-linux-2024:~#
修改ntp源
# /etc/chrony/chrony.conf
# See http://www.pool.ntp.org/join.html for more information.
pool ntp.ubuntu.com iburst maxsources 4
pool 0.ubuntu.pool.ntp.org iburst maxsources 1
pool 1.ubuntu.pool.ntp.org iburst maxsources 1
pool 2.ubuntu.pool.ntp.org iburst maxsources 2
这段配置指定了四个NTP服务器池,并设置了每个池的最大来源数量(maxsources):
pool ntp.ubuntu.com iburst maxsources 4:使用ntp.ubuntu.com作为时间服务器池,并设置最大来源数量为4。这意味着chronyd将从该池中最多获取4个时间服务器的时间同步信息。pool 0.ubuntu.pool.ntp.org iburst maxsources 1:使用0.ubuntu.pool.ntp.org作为第一个时间服务器池,并设置最大来源数量为1。这意味着chronyd将从该池中最多获取1个时间服务器的时间同步信息。pool 1.ubuntu.pool.ntp.org iburst maxsources 1:使用1.ubuntu.pool.ntp.org作为第二个时间服务器池,并设置最大来源数量为1。pool 2.ubuntu.pool.ntp.org iburst maxsources 2:使用2.ubuntu.pool.ntp.org作为第三个时间服务器池,并设置最大来源数量为2。
这些配置指定了多个NTP服务器池,以提高时间同步的可靠性和准确性。iburst选项表示在启动时快速进行时间同步。指定maxsources可以帮助限制chronyd从每个池中获取的时间服务器数量,以避免同时从太多
pool time1.tencentyun.com iburst
pool time2.tencentyun.com iburst
pool time3.tencentyun.com iburst
pool time4.tencentyun.com iburst
pool time5.tencentyun.com iburst
# 重启
root@yuchao-linux-2024:~# systemctl restart chrony
root@yuchao-linux-2024:~#
root@yuchao-linux-2024:~# !ps
ps -ef |grep -E 'ntp|chrony'
_chrony 1048286 1 0 16:39 ? 00:00:00 /usr/sbin/chronyd -F 1
_chrony 1048287 1048286 0 16:39 ? 00:00:00 /usr/sbin/chronyd -F 1
root 1048321 1045712 0 16:39 pts/8 00:00:00 grep --color=auto -E ntp|chrony
root@yuchao-linux-2024:~#
#
查看chrony状态
要查看chrony的同步状态,您可以使用chronyc命令。以下是一些常用的chronyc命令来查看chrony同步状态的信息:
查看chrony当前的同步状态和偏移量:
sudo chronyc tracking
这将显示chrony当前的同步状态、最后一次的偏移量、系统时钟频率的调整等信息。
查看chrony与服务器之间的时间偏移量:
sudo chronyc sources -v
这将显示chrony与每个时间服务器之间的时间偏移量,包括服务器的IP地址、时钟源的层级等信息。
查看chrony的系统状态信息:
sudo chronyc activity
这将显示chrony的系统状态信息,包括最近的NTP活动、最近的时钟频率调整等信息。
看状态
root@yuchao-linux-2024:~# chronyc tracking
Reference ID : A9FE004F (169.254.0.79)
Stratum : 3
Ref time (UTC) : Mon Mar 11 09:13:08 2024
System time : 0.000012994 seconds slow of NTP time
Last offset : +0.000101969 seconds
RMS offset : 0.000268691 seconds
Frequency : 1.167 ppm slow
Residual freq : +0.001 ppm
Skew : 0.353 ppm
Root delay : 0.000945434 seconds
Root dispersion : 0.027925424 seconds
Update interval : 64.4 seconds
Leap status : Normal
root@yuchao-linux-2024:~#
这是chronyc tracking命令的输出,显示了chrony当前的同步状态信息。以下是输出中各字段的含义:
Reference ID:参考时钟的标识符,通常是NTP服务器的IP地址。Stratum:NTP服务器的时钟层级,数字越低表示层级越高。Ref time (UTC):NTP服务器的参考时间(协调世界时)。System time:系统时钟与NTP时间之间的偏移量,单位为秒。Last offset:上一次时钟校准的偏移量,单位为秒。RMS offset:平均偏移量的均方根(Root Mean Square),用于估计时钟的稳定性。Frequency:时钟频率调整,以百万分之一为单位,表示系统时钟的漂移率。Residual freq:剩余频率偏移,即系统时钟频率的偏移率。Skew:时钟的斜率,用于估计时钟的变化速率。Root delay:从本地系统到参考时钟的总延迟,单位为秒。Root dispersion:本地系统与参考时钟之间的最大时钟偏移,用于估计时钟同步的精度。Update interval:更新间隔,即chrony向NTP服务器发送同步请求的时间间隔。Leap status:闰秒状态,通常为Normal表示没有闰秒插入。
从输出中可以看出,您的系统与NTP服务器的同步状态良好,系统时钟与NTP时间之间的偏移量很小,时钟频率的调整也在可接受范围内。
看偏移量
root@yuchao-linux-2024:~# chronyc sources -v
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current best, '+' = combined, '-' = not combined,
| / 'x' = may be in error, '~' = too variable, '?' = unusable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* 169.254.0.79 2 6 377 2 +578us[ +564us] +/- 43ms
^+ 169.254.0.80 2 6 377 3 +665us[ +651us] +/- 46ms
^+ 169.254.0.81 2 6 377 196 -167us[ -61us] +/- 36ms
^+ 169.254.0.82 2 8 377 3 -885us[ -900us] +/- 52ms
^+ 169.254.0.83 2 8 377 63 -673us[ -686us] +/- 49ms
root@yuchao-linux-2024:~#
这是chronyc sources -v命令的输出,显示了chrony正在使用的时间源的信息。以下是输出中各字段的含义:
Source mode:源模式,^表示服务器(server),=表示对等体(peer),#表示本地时钟(local clock)。Source state:源状态,*表示当前最佳(current best),+表示组合(combined),-表示未组合(not combined),x表示可能存在错误(may be in error),~表示变化过大(too variable),?表示无法使用(unusable)。MS Name/IP address:NTP服务器的名称或IP地址。Stratum:时钟层级。Poll:轮询间隔。Reach:可达性,表示最近8次通信中成功的次数(最大为377)。LastRx:最后一次收到数据包的时间。Last sample:最近一次的样本,包括已调整的偏移量和测量的偏移量,以及估计的误差范围。
从输出中可以看出,chrony正在使用多个时间源进行时间同步,并显示了每个时间源的相关信息,包括可达性、偏移量和误差范围等。这些信息有助于了解chrony与时间源之间的同步状态和时钟精度。
看激活状态
root@yuchao-linux-2024:~# chronyc activity
200 OK
5 sources online
0 sources offline
0 sources doing burst (return to online)
0 sources doing burst (return to offline)
35 sources with unknown address
root@yuchao-linux-2024:~#
这是chronyc activity命令的输出,显示了chrony当前的活动状态信息。以下是输出中各字段的含义:
200 OK:表示命令执行成功。5 sources online:表示有5个时间源处于在线状态,即正在与chrony同步时间。0 sources offline:表示没有时间源处于离线状态。0 sources doing burst (return to online):表示没有时间源正在进行爆发同步并返回在线状态。0 sources doing burst (return to offline):表示没有时间源正在进行爆发同步并返回离线状态。35 sources with unknown address:表示有35个时间源的地址未知,可能由于网络问题或配置错误导致。
这些信息可以帮助您了解chrony当前的时间同步状态和活动情况。
防火墙ufw服务
什么是防火墙
什么是防火墙
防火墙:防范一些网络攻击。有软件防火墙、硬件防火墙之分。
防火墙好比一堵真的墙,能够隔绝些什么,保护些什么。
防火墙的本义是指古代构筑和使用木制结构房屋的时候,为防止火灾的发生和蔓延,人们将坚固的石块堆砌在房屋周围作为屏障,这种防护构筑物就被称之为“防火墙”。其实与防火墙一起起作用的就是“门”。
如果没有门,各房间的人如何沟通呢,这些房间的人又如何进去呢?当火灾发生时,这些人又如何逃离现场呢?
这个门就相当于我们这里所讲的防火墙的“安全策略”,所以在此我们所说的防火墙实际并不是一堵实心墙,而是带有一些小孔的墙。
这些小孔就是用来留给那些允许进行的通信,在这些小孔中安装了过滤机制,就是防火墙的过滤策略了。
防火墙的作用
防火墙具有很好的保护作用。入侵者必须首先穿越防火墙的安全防线,才能接触目标计算机。
防火墙的功能
防火墙对流经它的网络通信进行扫描,这样能够过滤掉一些攻击,以免其在目标计算机上被执行。防火墙还可以关闭不使用的端口。而且它还能禁止特定端口的流出通信。
最后,它可以禁止来自特殊站点的访问,从而防止来自不明入侵者的所有通信。
防火墙概念
防火墙一般有硬件防火墙和软件防火墙
硬件防火墙:在硬件级别实现部分防火墙功能,另一部分功能基于软件实现,性能高,成本高。
软件防火墙:应用软件处理逻辑运行于通用硬件平台之上的防火墙,性能低,成本低。


windows防火墙
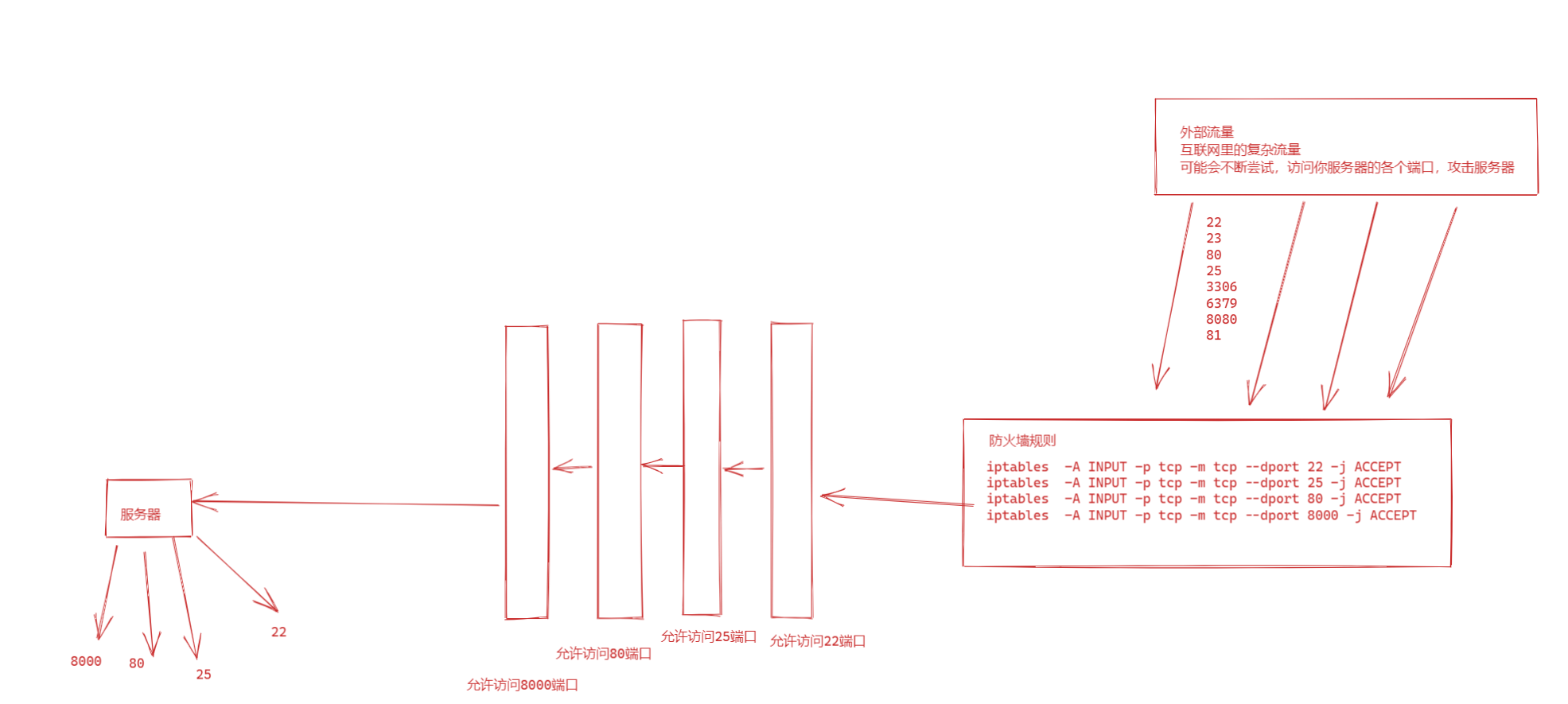
Linux防火墙(图解)
可见,服务器上有各种规则,限制什么请求可以进入到服务器
系统版本
centos iptables firewalld
ubuntu ufw
这是您系统的/etc/os-release文件的内容,提供了有关您正在使用的Ubuntu 22.04 LTS版本的详细信息:
PRETTY_NAME="Ubuntu 22.04 LTS":系统的漂亮名称,显示为“Ubuntu 22.04 LTS”。NAME="Ubuntu":操作系统的名称,即Ubuntu。VERSION_ID="22.04":Ubuntu的版本号,指示为22.04。VERSION="22.04 (Jammy Jellyfish)":Ubuntu版本的详细版本号和代号,显示为“22.04 (Jammy Jellyfish)”。VERSION_CODENAME=jammy:Ubuntu版本的代号,即Jammy Jellyfish。ID=ubuntu:操作系统的唯一标识符,即ubuntu。ID_LIKE=debian:操作系统的类似标识符,即类似于Debian。HOME_URL="https://www.ubuntu.com/":Ubuntu官方主页的网址。SUPPORT_URL="https://help.ubuntu.com/":Ubuntu支持页面的网址。BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/":Ubuntu错误报告页面的网址。PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy":Ubuntu隐私政策页面的网址。UBUNTU_CODENAME=jammy:Ubuntu的代号,即Jammy Jellyfish。
这些信息可以帮助您了解您正在使用的Ubuntu系统的版本和相关支持信息。
# os版本
root@yuchao-linux-2024:~# cat /etc/os-release
PRETTY_NAME="Ubuntu 22.04 LTS"
NAME="Ubuntu"
VERSION_ID="22.04"
VERSION="22.04 (Jammy Jellyfish)"
VERSION_CODENAME=jammy
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=jammy
root@yuchao-linux-2024:~#
ufw服务
Ubuntu 22.04(也称为Jammy Jellyfish)默认使用的防火墙是UFW(Uncomplicated Firewall),这是一个面向用户友好的前端,用于管理iptables防火墙规则。
下面我会提供一个简单的UFW防火墙运维手册,包括安装、配置、管理规则和监控。
UFW命令实战
Ubuntu 22.04 默认安装了UFW,但如果你的系统中没有,可以通过以下命令安装:
sudo apt update
sudo apt install ufw
# 看状态
root@yuchao-linux-2024:~# ufw status
Status: inactive
# 开启,关闭
sudo ufw enable
sudo ufw disable
root@yuchao-linux-2024:~# sudo ufw enable
Command may disrupt existing ssh connections. Proceed with operation (y|n)? y
Firewall is active and enabled on system startup
root@yuchao-linux-2024:~# ufw status
root@yuchao-linux-2024:~#
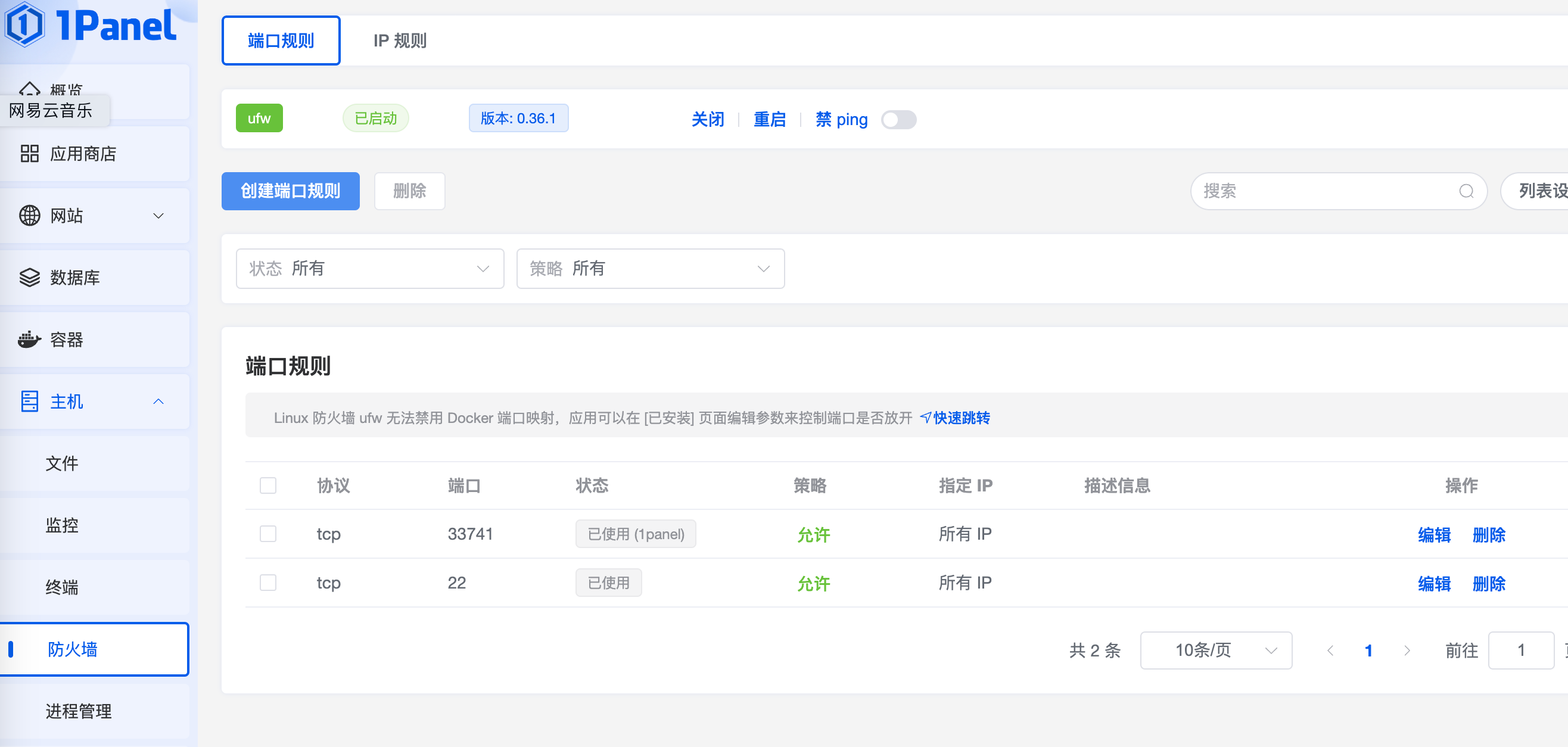
1panel看ufw
查看防火墙规则
root@yuchao-linux-2024:~# ufw status numbered
Status: active
To Action From
-- ------ ----
[ 1] 33741/tcp ALLOW IN Anywhere
[ 2] 33741/tcp (v6) ALLOW IN Anywhere (v6)
root@yuchao-linux-2024:~#
放行22端口,否则远程不了
root@yuchao-linux-2024:~# ufw allow 22/tcp
Rule added
Rule added (v6)
root@yuchao-linux-2024:~# ufw status numbered
Status: active
To Action From
-- ------ ----
[ 1] 33741/tcp ALLOW IN Anywhere
[ 2] 22/tcp ALLOW IN Anywhere
[ 3] 33741/tcp (v6) ALLOW IN Anywhere (v6)
[ 4] 22/tcp (v6) ALLOW IN Anywhere (v6)
root@yuchao-linux-2024:~#
配置默认规则
设置默认的防火墙策略。通常,拒绝所有传入连接,允许所有传出连接是个好的开始:
sudo ufw default deny incoming
root@yuchao-linux-2024:~# ufw default allow outgoing
Default outgoing policy changed to 'allow'
(be sure to update your rules accordingly)
root@yuchao-linux-2024:~#
添加和删除规则
添加规则允许特定端口(例如,允许HTTP通常是端口80):
sudo ufw allow 80/tcp
允许特定服务(UFW内置了一些服务名称与端口的映射):
sudo ufw allow http
删除规则(使用相同的语法,但是将allow换成delete):
sudo ufw delete allow 80/tcp
查看和管理规则
列出所有当前的规则:
sudo ufw status numbered
使用上述命令输出中的编号删除规则:
sudo ufw delete [number]
高级配置
- 允许来自特定IP地址的访问:
sudo ufw allow from 192.168.1.1 to any port 22
- 配置日志记录:
sudo ufw logging on
查看日志通常在/var/log/ufw.log。
- 配置NAT和端口转发:这需要编辑UFW的配置文件,通常位于
/etc/ufw/before.rules。
监控和故障排除
- 监控UFW日志:
tail -f /var/log/ufw.log
- 重置UFW配置(慎用,这将删除所有规则):
sudo ufw reset
常用命令归纳
以下是一些常用的ufw(Uncomplicated Firewall)命令,用于管理防火墙规则:
启用防火墙:
sudo ufw enable
禁用防火墙:
sudo ufw disable
查看防火墙状态:
sudo ufw status
允许特定端口的流量(例如,允许SSH服务):
sudo ufw allow ssh
或者指定端口号:
sudo ufw allow 22/tcp
允许特定IP地址访问特定端口:
sudo ufw allow from 192.168.1.100 to any port 80
拒绝特定端口的流量:
sudo ufw deny smtp
删除防火墙规则:
sudo ufw delete allow ssh
启用防火墙日志记录:
sudo ufw logging on
禁用防火墙日志记录:
sudo ufw logging off
重载防火墙规则:
sudo ufw reload
这些是ufw的一些常用命令,可以帮助您管理防火墙规则。使用ufw时,请确保您已经了解您的网络需求,并根据需要配置适当的规则。
常见软件,ufw管理
sudo ufw allow mysql
sudo ufw allow 80/tcp
sudo ufw allow 443/tcp
sudo ufw allow 6379/tcp
sudo ufw allow 8080/tcp
sudo ufw allow 5000/tcp
总结
以上是Ubuntu 22.04的UFW防火墙的基本运维指南。
根据你的具体需要,可能还需要查阅更详细的资料或UFW的man页面来了解更高级的配置选项。
通过合理配置和管理UFW,可以有效地保护你的系统不受未授权访问的影响。
关闭禁用ufw,且清理规则
sudo ufw disable
sudo ufw reset
root@yuchao-linux-2024:~# systemctl disable ufw
Synchronizing state of ufw.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install disable ufw
Removed /etc/systemd/system/multi-user.target.wants/ufw.service.
root@yuchao-linux-2024:~#
定时任务crontab

你每天是怎么起床的?有的人有女朋友,,或是男朋友,,而我是被穷醒的,,,
3点,清理玩家下线。
什么是计划任务: 后台运行,到了预定的时间就会自动执行的任务,前提是:事先手动将计划任务设定好。
周期性任务执行
- 比如夜里进行用户数据备份(夜里访问量较少,备份动作吃资源,影响用户访问)
- 游戏公司特殊
清空/tmp目录下的内容
- mysql数据库备份
- redis数据备份
- 定时获取系统的状态信息
- 定时每天进行时间同步
- 网站用户日志定时切割、备份
这就用到了crond服务。
计划任务的作用
作用:
操作系统不可能24 小时都有人在操作,有些时候想在指定的时间点去执行任务(例如:每天凌晨 2 点去重新启动Apache),此时不可能真有人每天夜里 2 点去执行命令,这就可以交给计划任务程序去执行操作了。
查看计划任务
==语法:# crontab 选项==
常用选项:
==-l:list,列出指定用户的计划任务列表==
==-e:edit,编辑指定用户的计划任务列表,简单来说,计划任务就是一个文件==
-u:user,指定的用户名,如果不指定,则表示当前用户
-r:remove,删除指定用户的计划任务列表
示例代码:列出当前用户的计划任务列表
root@yuchao-linux-2024:~# crontab -l
*/5 * * * * flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &'
编辑定时任务
root@yuchao-linux-2024:~# crontab -e
Select an editor. To change later, run 'select-editor'.
1. /bin/nano <---- easiest
2. /usr/bin/vim.basic
3. /usr/bin/vim.tiny
4. /bin/ed
Choose 1-4 [1]:
这是当您运行 crontab -e 命令时,系统提示您选择编辑器的界面。您可以按照以下说明进行选择:
- 输入
1并按下回车键,选择/bin/nano作为编辑器。Nano 是一个简单易用的文本编辑器,对于初学者来说是一个不错的选择。 - 如果您更喜欢使用其他编辑器,可以选择相应的数字。例如,输入
2并按下回车键选择/usr/bin/vim.basic,或者输入3选择/usr/bin/vim.tiny。 - 如果您对这些编辑器都不熟悉,可以选择
1使用 Nano 编辑器进行编辑。编辑器的选择只是用来编辑 crontab 文件,您可以根据自己的喜好选择任何一个编辑器。
语法
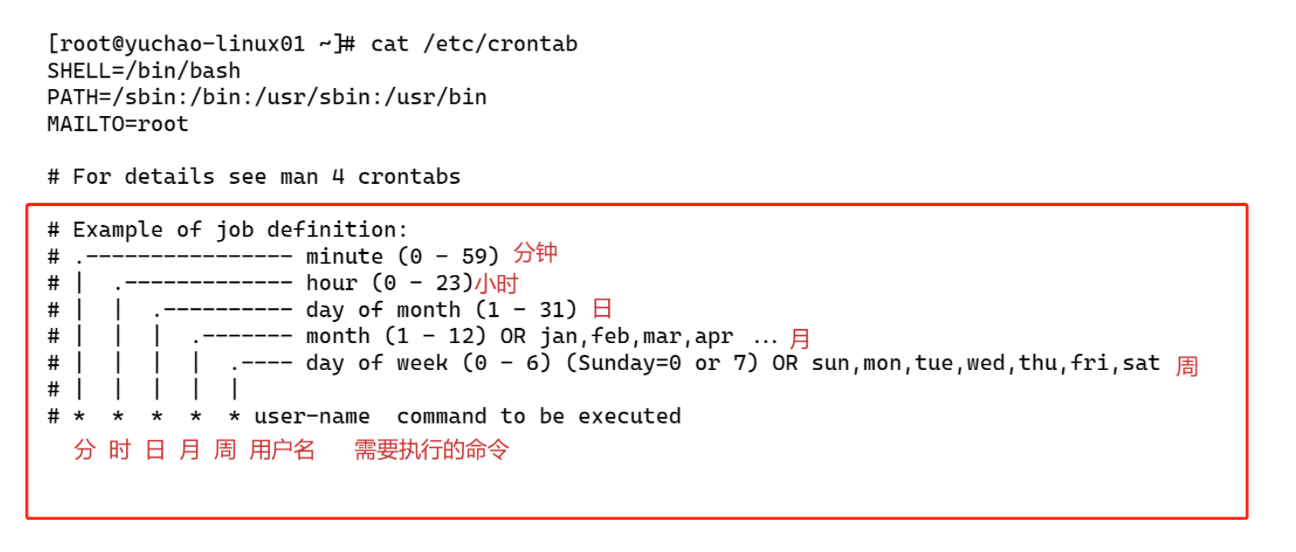
root@yuchao-linux-2024:~# cat /etc/crontab
# /etc/crontab: system-wide crontab
# Unlike any other crontab you don't have to run the `crontab'
# command to install the new version when you edit this file
# and files in /etc/cron.d. These files also have username fields,
# that none of the other crontabs do.
SHELL=/bin/sh
# You can also override PATH, but by default, newer versions inherit it from the environment
#PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
#
root@yuchao-linux-2024:~#
crontab 是用于在 Unix 和类 Unix 操作系统上运行定期任务的命令。以下是 crontab 的基本语法:
* * * * * command_to_execute
- - - - -
| | | | |
| | | | +----- Day of the week (0 - 7) (Sunday is both 0 and 7)
| | | +------- Month (1 - 12)
| | +--------- Day of the month (1 - 31)
| +----------- Hour (0 - 23)
+------------- Minute (0 - 59)
*表示匹配任意值,例如,*在分钟字段中表示每分钟执行一次。- 您可以使用逗号来指定多个值,例如,
1,15,30表示第 1、15 和 30 分钟。 - 您还可以使用连字符来指定一个范围,例如,
1-5表示第 1 到第 5 分钟。 /可以用来指定步长,例如,*/10表示每隔 10 分钟。
下面是一些示例:
- 每天凌晨 1 点执行任务:
0 1 * * * command_to_execute - 每月的第一天执行任务:
0 0 1 * * command_to_execute - 每小时执行任务:
0 * * * * command_to_execute - 每隔 5 分钟执行任务:
*/5 * * * * command_to_execute
注意:在 crontab 文件中,每行表示一个任务,可以使用 crontab -e 命令编辑 crontab 文件。
频率
在 crontab 中,*、-、/ 和 , 是用来指定任务执行时间的特殊字符:
*:代表匹配该字段的所有值。例如,*在分钟字段中表示每分钟执行一次。-:用于指定一个范围。例如,1-5在分钟字段中表示从第 1 分钟到第 5 分钟,相当于1,2,3,4,5。/:用于指定步长。例如,*/10在分钟字段中表示每隔 10 分钟执行一次。,:用于指定多个值。例如,1,15,30在分钟字段中表示在第 1、15 和 30 分钟执行任务。
这些特殊字符可以组合在一起使用,以便更灵活地定义任务执行时间。例如,1-5,10,15-20/5 在分钟字段中表示在第 1、2、3、4、5、10、15、20 分钟以及每隔 5 分钟执行一次。
练习题
0 0 * * * 每天0点执行 每天的零点整
分 时 日 月 周
* 0 * * * 每天的0点的每一分钟执行 00:00 00:01 00:02 00:03
15 1 * * * 每天夜里1点15分执行
分 时 日 月 周
15 1 * * *
每天下午1点15分执行
分 时 日 月 周
15 13 * * *
* * * * * 每分钟执行
0 * * * * 每小时整点执行
分 时 日 月 周
00:00
01:00
02:00
0 */2 * * * 每隔2小时执行
0 */2
*/30 * * * * 每隔30分钟执行
00 01 15 * * 每个月15号的夜里1点执行
00 05 1-14 * * 每个月的1到14号的凌晨5点执行
00 6-8 */5 * * 每隔5天的凌晨6-8点之间的整点执行
00 20-23/2 * * * 每天晚上8点到11点之间,每隔2小时的整点执行
8 9 10 11
分 时 日 月 周
0 20-23/2 * * *
00 23 * * 1-3 每周1到周三的晚上11点整执行
案例
以下是关于 nginx、MySQL、Redis、MongoDB、Docker、Kafka 和 NFS 等服务的 20 个 crontab 示例:
每天凌晨 3 点重启 Nginx 服务:
0 3 * * * systemctl restart nginx每周一凌晨 4 点备份 MySQL 数据库:
0 4 * * 1 mysqldump -u root -pPASSWORD DATABASE > /path/to/backup.sql每小时清理 Redis 缓存:
0 * * * * redis-cli -h HOST -p PORT FLUSHALL每天凌晨 2 点备份 MongoDB 数据库:
0 2 * * * mongodump -h HOST -d DATABASE -o /path/to/backup/directory每天凌晨 5 点清理 Docker 容器和镜像:
0 5 * * * docker container prune -f && docker image prune -f每周日凌晨 3 点重启 Kafka 服务:
0 3 * * 0 systemctl restart kafka每天凌晨 1 点同步 NFS 目录:
0 1 * * * rsync -avz /local/directory/ user@remote_server:/remote/directory/每小时检查 Nginx 运行状态并记录日志:
0 * * * * systemctl status nginx >> /var/log/nginx_status.log每天凌晨 4 点备份 MySQL 数据库到远程服务器:
0 4 * * * mysqldump -u root -pPASSWORD DATABASE | ssh user@remote_server 'cat > /path/to/backup.sql'每天凌晨 3 点清理 Redis 过期键:
0 3 * * * redis-cli -h HOST -p PORT KEYS "*" | xargs redis-cli -h HOST -p PORT DEL每天凌晨 2 点备份 MongoDB 数据库到远程服务器:
0 2 * * * mongodump -h HOST -d DATABASE | ssh user@remote_server 'cat > /path/to/backup/directory/backup.tar.gz'每周一凌晨 5 点清理 Docker 容器和镜像:
0 5 * * 1 docker container prune -f && docker image prune -f每周日凌晨 4 点重启 Kafka 服务并记录日志:
0 4 * * 0 systemctl restart kafka >> /var/log/kafka_restart.log每天凌晨 1 点同步 NFS 目录到远程服务器:
0 1 * * * rsync -avz /local/directory/ user@remote_server:/remote/directory/ >> /var/log/nfs_sync.log每小时检查 Nginx 运行状态并发送邮件通知:
0 * * * * systemctl status nginx | mail -s "Nginx Status" user@example.com每天凌晨 4 点备份 MySQL 数据库到云存储服务:
0 4 * * * mysqldump -u root -pPASSWORD DATABASE | aws s3 cp - s3://bucketname/backup.sql每天凌晨 3 点清理 Redis 缓存并记录日志:
0 3 * * * redis-cli -h HOST -p PORT FLUSHALL >> /var/log/redis_flush.log每天凌晨 2 点备份 MongoDB 数据库到云存储服务:
0 2 * * * mongodump -h HOST -d DATABASE | aws s3 cp - s3://bucketname/backup/directory/每周日凌晨 5 点清理 Docker 容器和镜像并记录日志:
0 5 * * 0 docker container prune -f && docker image prune -f >> /var/log/docker_cleanup.log每周一凌晨 4 点重启 Kafka 服务并发送短信通知:
0 4 * * 1 systemctl restart kafka && curl -X POST -d "message=Kafka restarted" https://sms-api.example.com/send
这些示例展示了如何使用 crontab 命令定期执行与 nginx、MySQL、Redis、MongoDB、Docker、Kafka 和 NFS 等服务相关的任务。请根据实际需求和环境进行适当调整。
案例2
Crontab 是一个非常强大的工具,可以帮助你自动化定期执行的任务。以下是针对 Nginx, MySQL, Redis, MongoDB, Docker, Kafka, NFS 等服务的 20 个 crontab 使用案例。这些案例涵盖了备份、监控、日志处理和系统维护等多个方面。
- Nginx 日志切割
每天凌晨对 Nginx 日志进行切割,避免单个日志文件过大。
0 0 * * * mv /var/log/nginx/access.log /var/log/nginx/access.log.$(date +\%Y\%m\%d) && nginx -s reload
- MySQL 数据库备份
每天凌晨备份 MySQL 数据库。
0 2 * * * mysqldump -u root -p'yourpassword' your_database | gzip > /path/to/backup/db_$(date +\%Y\%m\%d).sql.gz
- Redis 数据持久化备份
每6小时备份 Redis 数据库。
0 */6 * * * redis-cli bgsave
- MongoDB 备份
每天晚上备份 MongoDB。
0 3 * * * mongodump --out /path/to/backup/mongodb_$(date +\%Y\%m\%d)
- Docker 容器备份
每周一对所有运行中的 Docker 容器进行备份。
0 4 * * 1 docker ps -q | xargs -I {} docker commit {} /path/to/backup/{}_$(date +\%Y\%m\%d)
6.Kafka 消费者偏移量检查
每天检查 Kafka 消费者偏移量。
0 5 * * * /path/to/kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group your_consumer_group > /path/to/logs/kafka_consumer_offset_$(date +\%Y\%m\%d).log
- NFS 备份
每天备份 NFS 挂载目录。
0 2 * * * rsync -av /path/to/nfs/ /path/to/backup/nfs_backup_$(date +\%Y\%m\%d)/
- Nginx 服务状态检查
每小时检查 Nginx 服务状态,并重启如果它没有运行。
0 * * * * systemctl status nginx || systemctl restart nginx
- MySQL 表优化
每月一次对所有 MySQL 表进行优化。
0 3 1 * * mysqlcheck -o --all-databases -u root -p'yourpassword'
- Redis 内存碎片整理
每周日凌晨对 Redis 进行内存碎片整理。
0 0 * * 0 redis-cli --bigkeys
- MongoDB 日志切割
每天对 MongoDB 的日志文件进行切割。
0 0 * * * mongo admin --eval "db.runCommand({logRotate: 1})"
- Docker 未使用镜像清理
每周清理未使用的 Docker 镜像。
0 5 * * 0 docker system prune -a -f
- Kafka 日志清理
每天清理 Kafka 日志文件。
0 1 * * * find /var/log/kafka -type f -mtime +7 -exec rm {} \;
- NFS 挂载检查
每小时检查 NFS 挂载点,如果没有挂载则尝试重新挂载。
0 * * * * mountpoint -q /path/to/nfs || mount /path/to/nfs
- Nginx 配置测试
每天自动测试 Nginx 配置文件的有效性。
0 0 * * * nginx -t && systemctl reload nginx
- MySQL 从库同步状态检查
每天检查 MySQL 从库的同步状态。
0 6 * * * mysql -u root -p'yourpassword' -e 'SHOW SLAVE STATUS\G' > /path/to/logs/mysql_slave_status_$(date +\%Y\%m\%d).log
- Redis AOF文件重写
每月重写 Redis AOF 文件以优化性能。
0 0 1 * * redis-cli bgrewriteaof
- MongoDB 索引重建
每月自动重建 MongoDB 索引以保持查询效率。
0 2 1 * * mongo --eval "db.getCollectionNames().forEach(function(c) { db[c].reIndex(); });"
- Docker 容器健康检查
每天对所有 Docker 容器进行健康检查。
0 7 * * * docker ps -q | xargs -I {} docker inspect --format '{{.State.Health.Status}}' {} > /path/to/logs/docker_health_$(date +\%Y\%m\%d).log
- Kafka 服务监控
每小时检查 Kafka 服务的状态,并尝试重启如果它没有运行。
0 * * * * systemctl status kafka || systemctl restart kafka
这些 crontab 任务示例为你管理和维护常用的服务提供了一个起点。根据实际需求和环境,可能需要调整命令和计划的执行时间。
课程案例
学习定时任务,最简单的,就是直接通过案例,掌握其语法
综合基础问题
每天早上7:30起床学习
30 7 * * *
每隔3天,夜里2天,起来学习
0 2 */3 * *
夜里1点时候,每隔10分钟 起来吃点东西
*/10 1 * * *
夜里1点,3点,每隔10分钟 起来吃点东西
*/10 1,3 * * *
夜里1点到3点之间,每隔10分钟,起来吃点东西
*/10 1-3 * * *
每隔2个月的周六,夜里2点30 去见网友
30 2 * */2 6
结论
- 时间从左到右,依次写
- 具体日期和星期,不能同时出现
问题1:每月1、10、22 日的4:45 重启network 服务
45 4 1,10,22 * * /usr/bin/systemctl restart network
问题2:每周六、周日的1:10 重启network 服务
10 1 * * 6,7 /usr/bin/systemctl restart network
问题3:每天18:00 至23:00 之间每隔30 分钟重启network 服务
*/30 18-23 * * * /usr/bin/systemctl restart network
问题4:每隔两天的上午8 点到11 点的第3 和第15 分钟执行一次重启
3,15 8-11 */2 * * /usr/sbin/reboot
问题5 :每天凌晨整点重启nginx服务。
00 * * * * /usr/bin/systemctl restart nginx
问题6:每周4的凌晨2点15分执行命令
15 2 * * 4 command
问题7:工作日的工作时间内的每小时整点执行脚本。
00 9-18 * * 1-5 /usr/bin/bash my.sh
问题8:如果定时任务的时间,没法整除,定时任务就没有意义了,得通过其他手段,自主控制定时任务频率。
问题9:crontab提供最小分钟级别的任务,想完成秒级别的任务,得通过编程语言自己写。
问题10:每1分钟向文件里写入一句话"超哥666",且实时监测文件内容变化。
1.写入计划任务
crontab -e
2.写入语句
[root@yuchao-linux01 ~]# crontab -e
no crontab for root - using an empty one
crontab: installing new crontab
[root@yuchao-linux01 ~]#
[root@yuchao-linux01 ~]# crontab -l
* * * * * /usr/bin/echo '超哥666' >> /tmp/chaoge.txt
# 3.等待定时任务执行
[root@yuchao-linux01 ~]# tail -F /tmp/chaoge.txt
tail: cannot open ‘/tmp/chaoge.txt’ for reading: No such file or directory
tail: ‘/tmp/chaoge.txt’ has appeared; following end of new file
超哥666
超哥666
# 4. 删除用户的定时任务
crontab -r
问题11:每天凌晨2点30,执行ntpdate命令同步times.aliyun.com,并且sys同步到硬件时钟,且不输出任何信息。
1.ntpdate同步成功后,会生成同步的结果日志
[root@yuchao-linux01 ~]# ntpdate -u ntp.aliyun.com
可以重定向标准输出结果到黑洞文件,
ntpdate -u ntp.aliyun.com &> /dev/null
2.编写定时任务语句
30 2 * * * /usr/sbin/ntpdate -u ntp.aliyun.com &> /dev/null;/usr/sbin/hwclock -w &> /dev/null