什么是ansible
Ansible是一种自动化运维工具,用于管理和配置大规模计算机系统,包括服务器、网络设备和云资源等。它基于Python开发,通过SSH协议和模块化的架构,实现对远程主机的自动化操作和管理。
以下是Ansible的主要特点和功能:
- 基于SSH协议:Ansible使用SSH协议与远程主机通信,无需在远程主机上安装客户端软件,安全性高且易于部署。
- 基于模块化架构:Ansible采用模块化的架构,将系统管理任务分解为多个小的模块,如文件操作、软件包管理、服务管理等,可以根据需求选择合适的模块进行操作。
- 基于剧本(Playbook):Ansible使用YAML格式的剧本描述文件(Playbook),其中包含了一系列任务和操作,用于定义系统配置和管理的流程和步骤。
- 声明式语法:Ansible的剧本使用声明式语法,描述了系统的状态和期望结果,而非命令式的操作步骤,使得配置管理更加简洁和易于理解。
- 自动化部署:Ansible可以实现对软件部署和配置的自动化,包括安装、更新、配置和启动服务等操作,减少了手动操作的工作量和错误率。
- 灵活性和扩展性:Ansible支持自定义模块和插件,可以根据需求扩展功能和定制化操作,适用于不同的场景和环境。
- 可编程性:Ansible提供了丰富的API和开发工具,支持通过编程的方式实现自动化任务和集成其他系统。
- 跨平台支持:Ansible可以管理各种不同类型的系统和设备,包括Linux、Unix、Windows、网络设备、云服务等。
总的来说,Ansible是一款强大的自动化运维工具,具有简单易用、安全高效、灵活可扩展等特点,适用于管理和配置大规模的计算机系统,提高了系统管理的效率和可靠性。
为什么学ansible
学习Ansible有以下几个重要的原因:
- 自动化运维需求:随着IT基础设施规模的不断扩大和复杂度的增加,手工管理和配置已经无法满足快速变化的需求。学习Ansible可以帮助实现自动化运维,提高工作效率,减少人工成本和错误率。
- 提高工作效率:Ansible可以通过剧本(Playbook)实现对多台主机的统一管理和配置,自动化完成各种常见的系统管理任务,如软件部署、配置更新、服务启动等,大大提高了工作效率。
- 简化复杂性:Ansible采用声明式语法,将复杂的运维任务抽象为易于理解的模块化操作,简化了系统管理的复杂性,降低了学习和使用的难度。
- 提高系统稳定性:通过Ansible可以实现对系统的统一配置和管理,保证系统各个节点的一致性,减少了人为操作带来的配置错误,提高了系统的稳定性和可靠性。
- 适应云时代需求:随着云计算技术的发展,基础设施的动态性和可伸缩性成为了重要的考量因素。Ansible可以与各种云服务提供商(如AWS、Azure、Google Cloud等)无缝集成,实现自动化部署和管理,帮助企业更好地应对云时代的挑战。
- 提高竞争力:掌握Ansible等自动化运维工具的技能,可以使运维人员更具竞争力,提高就业机会和职业发展空间。
综上所述,学习Ansible是为了适应IT运维领域的发展趋势,提高工作效率,简化系统管理的复杂性,提高系统稳定性,同时也为个人职业发展增添了更多的机会和可能性。
ansible详解
Ansible是一种自动化运维工具,用于配置管理、应用部署、任务自动化等操作。以下是对Ansible的详细解释:
- 基于SSH协议:
- Ansible使用SSH协议与远程主机通信,无需在远程主机上安装客户端软件,可以直接通过SSH连接实现远程操作,保证了通信的安全性和可靠性。
- 剧本(Playbook):
- Ansible的核心概念是剧本(Playbook),剧本使用YAML格式编写,其中包含了一系列任务和操作,用于定义系统配置和管理的流程和步骤。剧本描述了系统的期望状态和所需操作,使得配置管理更加简洁和易于理解。
- 模块化架构:
- Ansible采用模块化的架构,将系统管理任务分解为多个小的模块,如文件操作、软件包管理、服务管理等,每个模块都可以独立执行,可以根据需要选择合适的模块进行操作。
- 声明式语法:
- Ansible的剧本使用声明式语法,描述了系统的状态和期望结果,而不是命令式的操作步骤,使得配置管理更加直观和易于理解,同时减少了人为错误的可能性。
- 模块化支持:
- Ansible提供了丰富的模块库,涵盖了各种系统管理任务的操作,如文件操作、软件包管理、服务管理、用户管理、数据库管理等,可以根据需要选择合适的模块进行操作。
- 主机组管理:
- Ansible支持对主机进行分组管理,可以将主机分组为不同的逻辑组,如web服务器组、数据库服务器组等,便于对不同类型的主机进行统一管理和操作。
- 变量和模板:
- Ansible支持使用变量和模板,可以将配置参数和模板文件存储在变量中,根据需要进行动态替换和配置,实现对配置的灵活管理和定制化操作。
- 自动化部署和配置管理:
- Ansible可以实现对软件部署和配置的自动化,包括安装、更新、配置和启动服务等操作,通过剧本的方式实现对多台主机的统一管理和操作,提高了工作效率和一致性。
综上所述,Ansible是一款强大的自动化运维工具,具有简单易用、安全高效、灵活可扩展等特点,适用于管理和配置大规模的计算机系统,帮助运维人员实现系统的自动化部署、配置管理和任务自动化,提高了工作效率和系统稳定性。
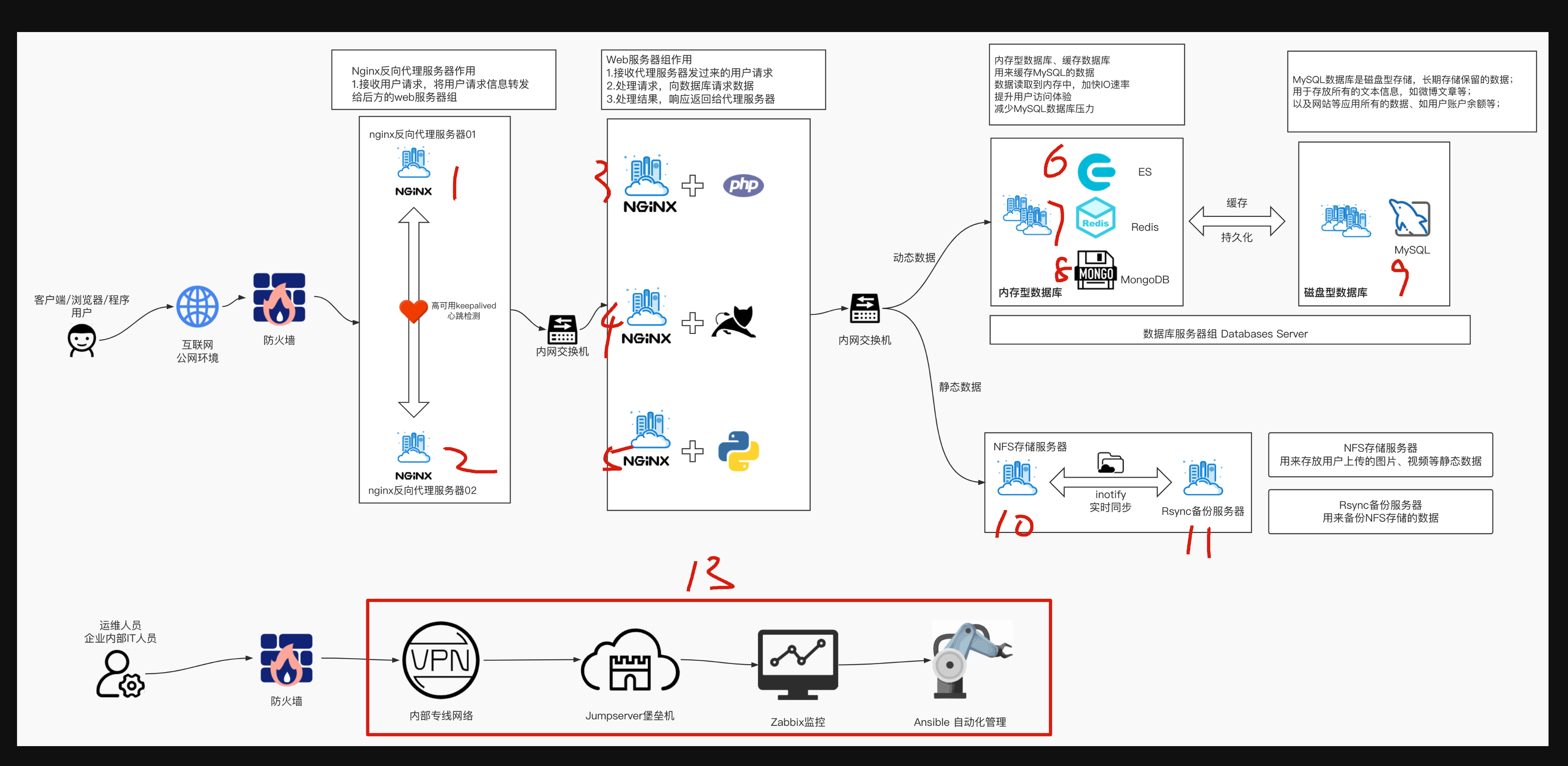
一句话,学好ansible,学精ansible,就直接是普通运维、和自动化运维的一个质的飞跃。

ansible提供了大量的模块、帮助运维完成服务器批量化部署操作,ansible你可以理解为这个是一个工具箱,这个工具是用来解决其他各种问题的。
1.冰箱坏了,你可以用螺丝刀自己慢慢拧,你也可以选择用电钻,几秒钟搞定
2.你要部署一台新nginx机器,你可以选择手动登录,逐条命令部署,你也可以用ansible几条命令搞定,并且可以复用,一瞬间搞定500台、5万台机器。
人工运维时代
人工运维时代指的是在云计算和自动化技术尚未普及之前,运维工作主要依赖人工进行管理和维护的时期。在人工运维时代,运维工作通常包括以下几个方面:
- 手工操作:大部分运维工作都是依靠手工操作完成的,例如手动部署和配置软件、手动监控系统运行状态、手动处理故障和异常等。
- 低效率:由于大部分工作都是依赖人工进行操作,运维效率较低,特别是对于大规模和复杂的系统,需要耗费大量的人力和时间。
- 易出错:人工操作容易出现失误,特别是在繁忙或压力下,可能导致配置错误、操作失误等问题,增加了系统故障和风险。
- 无法扩展:人工运维难以适应业务发展和系统规模的增长,随着业务的扩张和用户量的增加,运维工作量呈指数级增长,无法满足需求。
- 反应式维护:由于缺乏自动化工具和监控系统,运维工作主要是被动式的,只有在系统出现故障或异常时才会进行处理和维护。
尽管人工运维时代存在诸多不足之处,但在当时技术水平和自动化工具的发展尚未成熟的情况下,人工运维是维护系统稳定运行的主要手段。随着云计算、自动化技术和DevOps理念的发展,人工运维时代正在逐渐向自动化运维时代转变,运维工作逐渐实现自动化、智能化和可编程化,提高了运维效率和系统稳定性。
自动化运维时代
自动化运维时代是指在云计算、大数据和人工智能等技术的推动下,运维工作逐渐实现自动化、智能化和可编程化的时期。在自动化运维时代,运维工作发生了重大变革,具有以下几个显著特点:
- 自动化工具的普及:各种自动化运维工具如Ansible、Chef、Puppet、SaltStack等得到了广泛应用,大大简化了运维工作的流程和操作。
- 基础设施即代码(IaC):通过编程化的方式管理基础设施,将基础设施的定义和配置存储在代码中,实现了基础设施的自动化管理和可重复部署。
- 持续集成和持续部署(CI/CD):引入CI/CD工具和流程,实现了代码的自动化构建、测试和部署,缩短了软件开发周期,提高了交付速度和质量。
- 监控和告警系统:引入自动化监控和告警系统,实时监控系统的运行状态和性能指标,及时发现和解决问题,保证了系统的稳定性和可靠性。
- 容器化和微服务架构:采用容器化和微服务架构,实现了应用的快速部署、扩展和更新,提高了系统的灵活性和可伸缩性。
- 自动化运维平台:建立自动化运维平台,集成了各种自动化工具和流程,提供了统一的管理界面和操作接口,简化了运维管理的复杂性。
- 智能运维和预测性维护:引入人工智能和机器学习技术,实现了智能运维和预测性维护,通过数据分析和模型预测,提前发现和预防系统故障。
- DevOps文化的普及:倡导开发和运维团队的协作和共享,实现了开发、测试和运维的无缝集成,加速了软件交付和业务创新。
综上所述,自动化运维时代是运维工作从传统手工操作向自动化、智能化和可编程化转变的阶段,借助各种自动化工具和技术,实现了运维工作的高效管理和智能化运维,为企业提供了更高效、更稳定的IT基础设施和服务支持。
Anisble架构
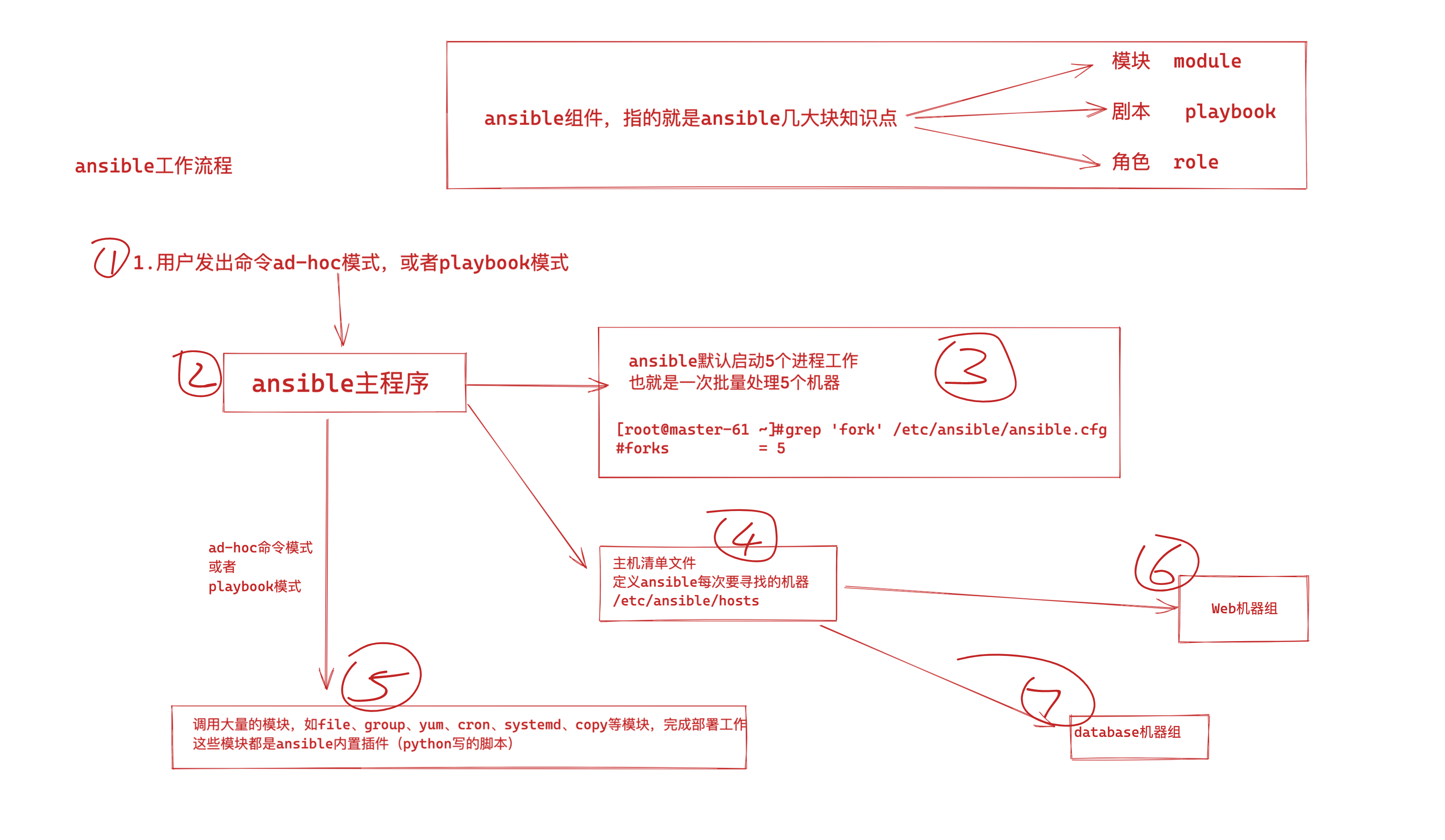
Ansible的架构相对简单而灵活,主要包括以下几个核心组件:
- 控制节点(Control Node):
- 控制节点是Ansible的主机,用于管理和控制整个Ansible系统。通常在控制节点上安装Ansible软件,并配置Ansible的相关设置,如主机清单文件、认证信息等。
- 被管节点(Managed Nodes):
- 被管节点是需要管理和操作的目标主机,可以是物理服务器、虚拟机、网络设备等各种类型的设备。Ansible通过SSH协议与被管节点通信,执行各种操作任务。
- 模块库(Module Library):
- 模块库包含了Ansible提供的各种模块,用于执行系统管理任务,如文件操作、软件包管理、服务管理等。每个模块都负责执行特定的任务,可以根据需要选择合适的模块进行操作。
- 剧本(Playbook):
- 剧本是Ansible的核心概念,是一个YAML格式的文件,包含了一系列任务和操作。剧本描述了系统的期望状态和所需操作,可以实现系统的自动化配置和管理。
- 插件系统(Plugin System):
- Ansible提供了丰富的插件系统,用于扩展和定制Ansible的功能和行为。用户可以编写自定义插件,实现特定的功能和操作,满足个性化的需求。
在Ansible的架构中,控制节点作为管理和控制的中心,负责向被管节点发送指令和执行任务;被管节点则是需要管理和操作的目标主机,负责接收并执行控制节点发送的任务;模块库提供了各种系统管理任务的模块,可以根据需要选择合适的模块进行操作;剧本是描述系统配置和管理的文件,用于实现自动化配置和管理。通过这些核心组件的协作,Ansible实现了简单而强大的自动化运维功能,为用户提供了高效、可靠的系统管理工具。
Anisble命令语法

ansible批量管理命令主要涉及6部分
- ansible主命令
- 指定ansible管理的主机信息,可以是主机组名、主机ip地址、或是
all - 调用ansible的模块参数
-m - 指定用哪一个功能模块,模块的名字,如shell模块
- 调用对应模块的功能参数,-a
- 执行对应模块中的哪些功能,如hostname
Ansible命令语法相对简单,通常由以下几个部分组成:
ansible [options] pattern [-m module_name] [-a "module_arguments"] [-i inventory_file]
下面是各部分的详细解释:
ansible:表示执行Ansible命令。[options]:可选参数,用于配置Ansible的行为,例如指定SSH用户名、指定使用的私钥文件、指定超时时间等。pattern:匹配模式,用于指定要执行操作的目标主机或主机组。可以使用IP地址、主机名、主机组名等作为匹配模式。-m module_name:指定要执行的模块名称,用于指定要在目标主机上执行的操作。例如,可以使用-m command指定执行命令模块,使用-m copy指定复制文件模块。-a "module_arguments":指定模块参数,用于传递给指定模块的参数值。参数值应放在双引号中,多个参数之间使用空格分隔。-i inventory_file:指定主机清单文件,用于指定要管理的主机和主机组。如果未指定主机清单文件,默认使用/etc/ansible/hosts文件作为主机清单。
例如,要在名为webserver的主机组上执行command模块,并执行ls -l命令,可以使用以下命令:
ansible webserver -m command -a "ls -l"
这条命令将会在webserver主机组中的所有主机上执行ls -l命令。
ansible ad-hoc 运维案例
Ad-hoc命令是在不使用Playbook的情况下,直接在命令行中执行的Ansible命令,通常用于临时性任务或者快速验证。
下面是一个简单的Ad-hoc运维案例,假设我们需要在一组Web服务器上查看系统信息:
ansible webservers -m command -a "uname -a"
这个命令将会连接到名为webservers的主机组中的所有主机,并执行uname -a命令,显示系统的内核版本和其他信息。
另一个例子,假设我们需要在一组服务器上查看当前系统时间:
ansible all -m command -a "date"
这个命令将会连接到所有主机,并执行date命令,显示当前系统时间。
Ad-hoc命令可以方便地执行一次性任务,但是不如Playbook灵活和可维护。因此,在正式的生产环境中,更推荐使用Playbook来管理和执行任务。
ansible安装部署
安装和部署Ansible通常包括在控制节点上安装Ansible软件,并配置Ansible的相关设置。下面是一般情况下的安装和部署步骤:
在Linux系统上安装Ansible
使用包管理工具安装:
在大多数Linux发行版上,可以使用包管理工具直接安装Ansible。例如,在基于Debian的系统(如Ubuntu)上,可以使用以下命令安装:
sudo apt update sudo apt install ansible在基于Red Hat的系统(如CentOS、Fedora)上,可以使用以下命令安装:
sudo yum install ansible
通过源代码安装:
- 可以从Ansible的官方网站下载源代码,并手动编译和安装。这种方式相对复杂,一般情况下不推荐使用,除非有特殊需求。
配置Ansible
编辑主机清单文件:
默认情况下,Ansible使用
/etc/ansible/hosts文件作为主机清单文件,用于定义要管理的主机和主机组。可以编辑该文件,添加要管理的主机信息。也可以创建自定义的主机清单文件,并通过 -i参数指定使用。例如:
ansible-playbook -i my_inventory_file.yml my_playbook.yml
配置SSH连接信息:
- Ansible使用SSH协议连接到被管节点,因此需要确保控制节点可以通过SSH连接到被管节点,并且可以免密登录。
- 可以通过SSH密钥认证或者密码认证来配置SSH连接信息。
其他配置选项:
- 可以根据需要配置其他的Ansible选项,如控制节点的认证信息、超时时间、日志级别等。可以通过编辑
/etc/ansible/ansible.cfg文件来进行配置。
- 可以根据需要配置其他的Ansible选项,如控制节点的认证信息、超时时间、日志级别等。可以通过编辑
测试Ansible连接
在完成安装和配置之后,可以通过执行一些简单的Ad-hoc命令或者Playbook来测试Ansible的连接和功能。例如,可以执行以下命令来测试连接到所有主机并获取系统信息:
ansible all -m command -a "uname -a"
如果一切正常,应该能够看到所有主机的系统信息输出。
以上是基本的Ansible安装和部署过程。具体的步骤可能会根据不同的操作系统和环境有所不同,建议根据实际情况进行相应的调整和配置。
ansible.cfg案例
下面是一个简单的 ansible.cfg 文件的示例,其中包含了一些常用的配置选项:
[defaults]
# 指定要使用的主机清单文件路径
inventory = /etc/ansible/hosts
# 指定默认的远程用户
remote_user = ansible
# 指定SSH私钥文件路径
private_key_file = ~/.ssh/id_rsa
# 指定Ansible模块的路径
module_utils = /usr/share/my_modules
# 设置SSH连接超时时间
timeout = 30
# 设置任务执行的并发数量
forks = 10
# 是否显示未变更的任务结果
nocolor = 1
在这个配置文件中:
[defaults]段指定了默认的配置选项。inventory指定了主机清单文件的路径,这里默认为/etc/ansible/hosts。remote_user指定了默认的远程用户,这里设置为ansible。private_key_file指定了SSH私钥文件的路径,这里设置为~/.ssh/id_rsa。module_utils指定了Ansible模块的路径,这里设置为/usr/share/my_modules。timeout设置了SSH连接的超时时间,这里设置为30秒。forks设置了任务执行的并发数量,这里设置为10。nocolor设置为1表示不显示未变更的任务结果,即只显示发生了变更的任务结果。
根据实际需求,可以根据文档提供的其他配置选项,对 ansible.cfg 文件进行定制。
/etc/ansible/hosts
/etc/ansible/hosts 文件是 Ansible 的主机清单文件,用于定义被管理的主机和主机组。下面是一个简单的示例:
# 注意要安装 apt install sshpass -y
root@yu:~# cat /etc/ansible/hosts
[all]
192.168.234.131 ansible_password=123123 ansible_user=root
root@yu:~#
在这个示例中,我们定义了两个主机组 [web_servers] 和 [db_servers],并分别列出了属于这两个组的主机。web1.example.com、web2.example.com 和 web3.example.com 属于 web_servers 组,而 db1.example.com 和 db2.example.com 属于 db_servers 组。
您可以根据您的实际环境和需要,编辑 /etc/ansible/hosts 文件,并根据主机的角色或功能将其分组,以便在执行 Ansible 命令时进行区分和选择。
主机清单文件规则
/etc/ansible/hosts 文件是 Ansible 的主机清单文件,用于定义要管理的主机和主机组。在这个文件中,您可以指定主机的 IP 地址、主机名、连接方式、用户名、密码等信息,并将它们分组,以便在执行 Ansible 命令时进行选择和操作。
以下是 /etc/ansible/hosts 文件的一般规则:
注释:使用
#符号来添加注释,可以帮助您和其他管理员理解清单的结构和内容。主机组:您可以使用方括号
[]来定义主机组,然后在该主机组下列出该组中的所有主机。例如:[web_servers] web1.example.com web2.example.com主机定义:在主机组下,列出该组中的所有主机。您可以指定主机的 IP 地址、主机名或域名。例如:
[web_servers] 192.168.1.101 192.168.1.102指定连接方式:您可以在主机定义后使用
ansible_connection参数来指定连接方式。常用的连接方式包括ssh、winrm等。例如:[web_servers] 192.168.1.101 ansible_connection=ssh 192.168.1.102 ansible_connection=ssh指定用户名和密码:如果需要,您可以在主机定义后使用
ansible_user和ansible_password参数来指定连接到远程主机时使用的用户名和密码。例如:[web_servers] 192.168.1.101 ansible_connection=ssh ansible_user=myuser ansible_password=mypassword添加变量:您可以使用
:符号和key=value格式在主机定义后指定变量。例如:[web_servers] 192.168.1.101 ansible_connection=ssh ansible_user=myuser ansible_password=mypassword my_custom_variable=value包含其他清单文件:您可以使用
include参数来包含其他的主机清单文件。例如:[web_servers] 192.168.1.101 ansible_connection=ssh ansible_user=myuser ansible_password=mypassword [db_servers] 192.168.1.201 ansible_connection=ssh ansible_user=myuser ansible_password=mypassword [all:vars] my_variable=value [other_group] localhost ansible_connection=local [include] /path/to/other_inventory_file
这些是您可以在 Ansible 主机清单文件中使用的一般规则。通过适当的组织和配置,您可以更有效地管理和执行 Ansible 任务。
ad-hoc模式
Ad-hoc模式是Ansible的一种运行模式,可以在命令行中直接执行单个任务而不需要编写Playbook。下面是一些Ad-hoc模式的常见用法和示例:
- Ping测试:使用
ping模块检查目标主机是否可达。
ansible all -m ping
- 执行命令:在目标主机上执行命令。
ansible all -a "ls -l"
- 安装软件包:在目标主机上安装软件包。
ansible all -m apt -a "name=nginx state=present" --become
- 复制文件:将本地文件复制到目标主机。
ansible all -m copy -a "src=/path/to/local/file dest=/remote/destination/file" --become
- 重启服务:在目标主机上重启指定的服务。
ansible all -m service -a "name=nginx state=restarted" --become
- 添加用户:在目标主机上添加用户。
ansible all -m user -a "name=myuser state=present" --become
- 查看磁盘空间:在目标主机上查看磁盘空间使用情况。
ansible all -m shell -a "df -h"
这些示例演示了如何在Ad-hoc模式下使用不同的模块执行不同的任务。您可以根据自己的需求修改命令和参数,以执行特定的操作。
什么是playbook
Playbook是Ansible的核心概念之一,是用于定义一系列任务的文件,用于自动化配置管理和系统管理。
一个Playbook文件是一个YAML格式的文本文件,其中定义了一组任务以及任务的执行顺序、主机和变量等信息。每个任务通常会涉及到在目标主机上执行一个或多个模块,实现特定的配置或操作。
Playbook文件通常由以下几个部分组成:
- 主机清单(Host Inventory):定义了要管理的主机和主机组,可以是IP地址、主机名或者主机组名称。
- 变量定义(Variable Definitions):定义了在Playbook中使用的变量,用于动态地传递参数和配置信息。
- 任务列表(Task List):包含了一系列要执行的任务,每个任务由一个或多个模块组成,用于执行特定的操作。
- 处理逻辑(Control Logic):定义了任务执行的条件、循环、异常处理等逻辑。
- 剧本元数据(Playbook Metadata):包含了Playbook的名称、作者、版本等元数据信息。
通过编写Playbook文件,用户可以实现系统的自动化配置和管理,提高了管理效率和一致性,并且可以轻松地重复使用和分享。Playbook文件是Ansible自动化运维的重要组成部分,是实现自动化操作的核心工具之一。
为什么学playbook
学习使用Playbooks的原因有很多,特别是在DevOps、自动化和配置管理方面。以下是学习Playbooks的一些主要原因:
- 自动化任务: Playbooks允许您定义和执行一系列自动化任务,从而减少手动操作的需求。这样可以提高效率,并减少人为错误的风险。
- 配置管理: 使用Playbooks可以对系统进行配置管理,确保系统和应用程序的状态符合预期。这对于保持环境一致性和可维护性非常重要。
- 部署应用程序: 通过Playbooks,您可以定义应用程序的部署过程,从而简化和标准化部署流程。这对于快速部署和更新应用程序至关重要。
- 灵活性: Playbooks提供了丰富的语法和功能,使您能够灵活地定义各种任务和工作流程,以满足特定需求。
- 版本控制: Playbooks可以与版本控制系统(如Git)集成,使您能够跟踪对基础设施配置的更改,并轻松回滚到先前的状态。
- 文档化: 编写Playbooks时,通常需要记录任务和操作的细节,这有助于创建基础设施的文档,并使操作过程更透明和易于理解。
- 可扩展性: Ansible的Playbooks可以与其他工具和平台集成,从而扩展其功能,例如与CI/CD工具、云平台和监控系统集成,以实现更高级的自动化。
总的来说,学习使用Playbooks可以使您更好地管理基础设施和应用程序,并提高工作效率,从而在DevOps环境中发挥更大的作用。
playbook详解
Playbook是Ansible中用于定义一系列任务的文档格式。它由一个或多个剧本(plays)组成,每个剧本包含了一组相关的任务。下面是一个典型的Playbook的结构及其详细说明:
Playbook 结构
---
- name: Playbook 示例 # Playbook的名称
hosts: all # 指定要执行任务的主机或主机组
become: true # 指定是否要以特权用户(如root)身份运行任务
tasks: # 包含一系列任务的列表
- name: 任务1 # 任务的名称
<module>: # 使用的Ansible模块
<parameter>: <value> # 模块参数及其取值
- name: 任务2
<module>:
<parameter>: <value>
# 可以包含更多的任务...
# 可以包含更多的剧本...
Playbook 详解
- name: Playbook的名称,描述了Playbook的用途或目标。
- hosts: 指定要执行任务的目标主机或主机组。可以使用逗号分隔的列表、主机模式(例如
all、localhost、web_servers等)或使用通配符指定一组主机。 - become: 指定是否要以特权用户(如root)身份运行任务。通常在执行需要特权的操作时设置为true。
- tasks: 包含了一系列任务的列表,每个任务由一个或多个模块组成。
- name: 任务的名称,描述了任务的目标或操作。
- module: 使用的Ansible模块,用于执行任务。模块包含了要执行的具体操作,例如文件操作、软件包管理、服务管理等。
- parameter: 模块参数,用于指定模块的行为。每个模块都有一组特定的参数,用于控制其行为。
示例
下面是一个简单的Playbook示例,用于在目标主机上安装nginx服务器:
---
- name: 安装 nginx
hosts: web_servers
become: true
tasks:
- name: 安装 nginx 软件包
apt:
name: nginx
state: present
become: true
在此示例中,Playbook名称为"安装 nginx",指定了目标主机组为web_servers,然后执行了一个任务,即使用apt模块安装nginx软件包。
yaml语法详解
YAML(YAML Ain't Markup Language)是一种人类可读的数据序列化格式,经常用于配置文件、数据交换和存储。它的设计目标是易于阅读和编写。下面是 YAML 的语法详解:
1. 基本结构
YAML 使用缩进来表示数据结构,类似于 Python。缩进用空格表示,不同层级的数据使用不同数量的空格缩进。通常使用两个空格作为缩进。
2. 键值对
YAML 主要由键值对组成,使用冒号 : 分隔键和值。键值对的键可以是字符串或者不带引号的字符串,但如果键包含特殊字符或空格,最好使用引号包围。
name: John
age: 30
3. 列表
YAML 支持列表,使用短横线 - 表示列表项。列表项可以是任何数据类型,包括字符串、数字、布尔值、嵌套的键值对等。
fruits:
- apple
- banana
- orange
4. 嵌套结构
YAML 允许在一个键值对的值中嵌套其他键值对或列表,可以创建复杂的数据结构。
person:
name: John
age: 30
address:
city: New York
street: 123 Main St
hobbies:
- reading
- hiking
5. 注释
YAML 支持注释,在行的开头使用井号 # 表示注释。注释可以出现在行的开头,也可以出现在行的结尾。
# This is a comment
name: John # This is also a comment
6. 多行字符串
YAML 支持多行字符串,可以使用 | 符号来表示保留换行符,也可以使用 > 符号表示折叠换行符。
description: |
This is a long
multiline
string.
7. 引用
YAML 支持引用其他节点的值,使用 & 表示节点的别名,使用 * 表示引用节点。
person: &details
name: John
age: 30
another_person:
<<: *details
以上是 YAML 的基本语法。通过阅读文档、练习和查看示例,你可以更深入地了解 YAML 的语法和用法。
JSON语法
JSON(JavaScript Object Notation)是一种用于数据交换的轻量级数据格式,常用于Web开发中。它基于JavaScript语法的子集,但可以在许多编程语言中解析和生成。以下是JSON语法的详解:
1. 数据类型
JSON支持以下数据类型:
- 字符串(String):由双引号括起来的Unicode字符序列,例如:"Hello, World!"。
- 数字(Number):包括整数和浮点数,不支持NaN和Infinity。
- 布尔值(Boolean):true或false。
- 数组(Array):有序的值的集合,使用方括号括起来,例如:[1, 2, 3]。
- 对象(Object):无序的键值对的集合,使用花括号括起来,例如:{"name": "John", "age": 30}。
- 空值(null):表示空值,使用null表示。
2. 键值对
JSON中的对象由键值对组成,键和值之间使用冒号分隔,键值对之间使用逗号分隔。键必须是字符串,值可以是任何JSON支持的数据类型。示例:
{
"name": "John",
"age": 30,
"isStudent": false
}
3. 数组
JSON数组是由一组按顺序排列的值组成的,使用方括号括起来,值之间使用逗号分隔。数组可以包含不同类型的值。示例:
[1, 2, "three", {"key": "value"}]
4. 嵌套
JSON支持嵌套结构,可以在对象中嵌套对象,或在数组中嵌套数组或对象,以创建复杂的数据结构。示例:
{
"person": {
"name": "John",
"age": 30,
"address": {
"city": "New York",
"zip": "10001"
}
},
"hobbies": ["reading", "hiking"]
}
5. 注释
JSON不支持注释,任何带有注释的JSON都将被视为无效。
6. 空格和换行
JSON对空格和换行不敏感,可以使用空格和换行来提高可读性,但不会影响JSON的解析。
这些是JSON语法的基本要点,了解这些将有助于你理解和编写JSON数据。 JSON的简洁性和通用性使其成为一种流行的数据交换格式。
playbook实战案例
下面是一个简单的 Ansible playbook 实战案例,用于在远程服务器上安装 Nginx 服务并启动它:
---
- name: Install and start Nginx
hosts: your_servers
become: yes # 使用sudo权限执行任务
tasks:
- name: Update apt cache
apt:
update_cache: yes # 更新apt包管理器的软件包缓存
become: yes
- name: Install Nginx
apt:
name: nginx # 安装Nginx软件包
state: present # 确保软件包已安装
become: yes
- name: Start Nginx service
service:
name: nginx # 启动Nginx服务
state: started # 确保服务已启动
become: yes
解释:
name: 定义了这个playbook的名称。hosts: 指定了目标主机组,你需要在your_servers处指定你的目标主机,可以是一个单独的主机或主机组。become: yes: 表示使用sudo权限执行任务。tasks: 定义了一系列任务。apt: Ansible 的 apt 模块,用于在 Ubuntu 或 Debian 系统上安装软件包。update_cache: yes表示更新apt包管理器的软件包缓存。name: nginx表示安装Nginx软件包。state: present表示确保软件包已安装。service: Ansible 的 service 模块,用于管理系统服务。name: nginx表示操作Nginx服务。state: started表示确保服务已启动。
要运行此playbook,你需要将它保存为一个文件(例如 install_nginx.yaml),然后使用 ansible-playbook 命令运行:
ansible-playbook install_nginx.yaml
前提条件是你已经配置了 Ansible,并且目标主机已经设置好了 SSH 连接。
LNMP剧本
---
- name: Deploy LNMP stack
hosts: your_servers
become: yes
vars:
nginx_sites:
- name: example.com
root: /var/www/example.com
index: index.php index.html
mysql_root_password: your_mysql_root_password
php_packages:
- php-fpm
- php-mysql
- php-cli
- php-common
- php-gd
- php-curl
tasks:
- name: Update apt cache
apt:
update_cache: yes
- name: Install Nginx
apt:
name: nginx
state: present
- name: Install MySQL
apt:
name: mysql-server
state: present
vars:
mysql_root_password: ""
become_user: root
- name: Install PHP and required modules
apt:
name: ""
state: present
loop: ""
- name: Configure Nginx sites
template:
src: nginx_site.conf.j2
dest: "/etc/nginx/sites-available/"
with_items: ""
notify: Reload Nginx
- name: Enable Nginx sites
file:
src: "/etc/nginx/sites-available/"
dest: "/etc/nginx/sites-enabled/"
state: link
with_items: ""
notify: Reload Nginx
- name: Ensure Nginx is started and enabled
service:
name: nginx
state: started
enabled: yes
- name: Ensure MySQL is started and enabled
service:
name: mysql
state: started
enabled: yes
- name: Restart PHP-FPM service
service:
name: php7.4-fpm
state: restarted
handlers:
- name: Reload Nginx
service:
name: nginx
state: reloaded
什么是Role
在Ansible中,Role是一种组织和封装playbooks中任务的方法。它可以让你将相关的任务、变量和文件组织成一个可重用的单元,以便在多个playbooks中共享和重复使用。
Role通常用于将一个复杂的任务分解为更小的、更易管理的部分。一个Role通常包括以下几个主要组件:
- Tasks(任务): 包含执行特定操作的Ansible任务的列表,如安装软件包、配置服务等。
- Handlers(处理程序): 包含在任务执行后触发的操作,通常用于重新加载服务或执行其他相关操作。
- Variables(变量): 用于定义角色中使用的变量,这些变量可以在任务和模板中使用,使角色更加灵活和可配置。
- Templates(模板): 可选的,包含要在目标主机上渲染的Jinja2模板文件。
- Files(文件): 可选的,包含要复制到目标主机的文件。
- Defaults(默认变量): 可选的,包含角色默认变量的值。
- Meta(元数据): 包含描述角色的元数据信息,如作者、依赖关系等。
通过将任务、变量和文件组织成Role,可以更好地组织和管理Ansible代码,并使代码更易于重用和维护。Roles还可以通过Ansible Galaxy(一个Ansible角色的集中存储库)进行共享,让用户轻松地找到并使用他人编写的角色。
为什么学Role
学习 Ansible 的 Role 具有以下几个重要的理由:
- 模块化和可重用性:Role 将任务、变量和文件组织成一个单独的单元,使得你可以将其作为一个整体来重用和共享。这种模块化的设计使得管理和维护 Ansible 代码变得更加简单和高效。
- 简化任务管理:通过将复杂的任务分解为更小、更易管理的部分,Role 可以帮助你更清晰地组织你的任务,并使得整个自动化流程更容易理解和维护。
- 提高可读性:Role 可以使你的 Ansible playbooks 更易读,因为它将相关的任务和变量组织在一起,使得代码更具结构性和清晰性。
- 促进协作:当你的自动化任务需要与其他团队成员共享或协作时,使用 Role 可以使得团队成员更容易理解和扩展你的代码,因为他们可以直接使用你编写的 Role,而不需要深入理解整个 playbooks 的细节。
- 简化维护:通过将常见的操作封装成 Role,你可以在不同的项目中重复使用这些 Role,从而节省时间和精力。当需要对某个操作进行更新或修复时,只需更新 Role 即可,而不需要修改所有相关的 playbooks。
- 提高效率:Role 可以帮助你快速构建自动化任务,因为它们提供了一种规范化的方式来组织和管理 Ansible 代码,从而减少了重复工作和错误的可能性。
总之,学习 Ansible 的 Role 对于提高自动化管理的效率、可维护性和可读性都非常重要,特别是在处理复杂的任务和大规模的基础架构时。
role详解
Ansible 的 Role 是一种组织和封装 Ansible playbook 中任务、变量和文件的方法,用于实现可重用的自动化模块。一个 Role 可以包含多个任务,每个任务可以实现特定的功能,而变量和文件则提供了配置和资源。
以下是一个典型的 Ansible Role 结构:
my_role/
├── defaults/
│ └── main.yml
├── files/
│ └── my_file.txt
├── handlers/
│ └── main.yml
├── meta/
│ └── main.yml
├── tasks/
│ └── main.yml
├── templates/
│ └── my_template.j2
├── vars/
│ └── main.yml
└── README.md
- defaults/: 包含 Role 的默认变量,这些变量可以在 Role 中的任务和模板中使用,可以在 playbook 中覆盖。
- files/: 包含 Role 使用的静态文件,这些文件会被复制到目标主机上。
- handlers/: 包含 Role 使用的处理程序,这些处理程序在任务执行后触发,通常用于重新加载服务或执行其他相关操作。
- meta/: 包含 Role 的元数据信息,如作者、依赖关系等。
- tasks/: 包含 Role 的任务,这些任务定义了 Role 实现的具体功能。
- templates/: 包含 Role 使用的模板文件,这些模板文件会在目标主机上渲染,生成最终的配置文件。
- vars/: 包含 Role 的变量文件,这些变量可以在 Role 中的任务和模板中使用,用于定义 Role 的配置参数。
- README.md: 包含 Role 的说明文档,用于描述 Role 的用途、配置参数等信息。
通过组织成 Role,可以更好地管理和维护 Ansible 代码,提高代码的可读性和可维护性,并使得代码更易于重用和共享。可以使用 Ansible Galaxy(一个 Ansible Role 的集中存储库)来查找和共享 Role,从而加速自动化任务的开发和部署。
role部署LNMP
下面是一个简单的示例,演示如何使用 Ansible Role 部署 LNMP(Linux + Nginx + MySQL + PHP)。
首先,我们需要创建一个名为 lnmp 的 Role,目录结构如下所示:
lnmp/
├── defaults
│ └── main.yml
├── handlers
│ └── main.yml
├── meta
│ └── main.yml
├── tasks
│ ├── install_nginx.yml
│ ├── install_mysql.yml
│ ├── install_php.yml
│ └── main.yml
├── templates
│ └── nginx_site.conf.j2
└── vars
└── main.yml
接下来,我们来逐一说明每个部分的内容:
defaults/main.yml: 包含默认变量,可以在 Role 中的任务和模板中使用。例如:
nginx_sites: - name: example.com root: /var/www/example.com index: index.php index.html mysql_root_password: your_mysql_root_passwordhandlers/main.yml: 包含处理程序,用于在任务执行后触发。在本例中,我们不需要处理程序。
meta/main.yml: 包含元数据信息,如作者、依赖关系等。在本例中,可以留空。
tasks/main.yml: 包含主要的任务列表,用于定义 LNMP 的安装过程。该文件将引用其他任务文件。
--- - include_tasks: install_nginx.yml - include_tasks: install_mysql.yml - include_tasks: install_php.ymltasks/install_nginx.yml: 包含安装 Nginx 的任务。例如:
--- - name: Install Nginx apt: name: nginx state: presenttasks/install_mysql.yml: 包含安装 MySQL 的任务。例如:
--- - name: Install MySQL apt: name: mysql-server state: present vars: mysql_root_password: "" become_user: roottasks/install_php.yml: 包含安装 PHP 的任务。例如:
--- - name: Install PHP and required modules apt: name: "" state: present loop: ""templates/nginx_site.conf.j2: 包含 Nginx 站点配置模板,用于生成配置文件。例如:
server { listen 80; server_name ; root ; index ; location / { try_files $uri $uri/ /index.php?$query_string; } location ~ \.php$ { include snippets/fastcgi-php.conf; fastcgi_pass unix:/var/run/php/php7.4-fpm.sock; } }vars/main.yml: 包含 Role 的变量,例如 PHP 相关的变量。例如:
php_packages: - php-fpm - php-mysql - php-cli - php-common - php-gd - php-curl
接下来,在你的 playbook 中使用这个 Role:
---
- name: Deploy LNMP stack
hosts: your_servers
become: yes
roles:
- lnmp
这样就可以通过这个 Role 部署 LNMP 环境了。确保替换 your_servers 和其他变量为实际的值,并根据需要修改 Role 中的任务和变量。