Linux工作常用命令
在 Linux 中,有许多常用的命令可用于执行各种任务,包括文件管理、系统管理、网络管理等。以下是一些常用的 Linux 命令:
- 文件和目录操作:
ls: 列出目录内容。cd: 切换目录。pwd: 显示当前工作目录。mkdir: 创建新目录。touch: 创建新文件或更新文件的访问和修改时间戳。cp: 复制文件和目录。mv: 移动或重命名文件和目录。rm: 删除文件和目录。cat: 查看文件内容。more或less: 分页查看文件内容。grep: 在文件中搜索指定模式。find: 在文件系统中查找文件。
- 系统管理:
ps: 显示当前运行的进程。top: 实时显示系统资源使用情况和进程信息。kill: 终止进程。shutdown: 关闭系统。reboot: 重启系统。uname: 显示系统信息。df: 显示磁盘空间使用情况。du: 显示目录或文件的磁盘使用情况。free: 显示系统内存使用情况。chmod: 修改文件权限。chown: 修改文件所有者和组。passwd: 修改用户密码。
- 用户和组管理:
useradd: 添加新用户。userdel: 删除用户。usermod: 修改用户属性。groupadd: 添加新用户组。groupdel: 删除用户组。groupmod: 修改用户组属性。
- 网络管理:
ifconfig: 显示或配置网络接口信息(已废弃,在新版本中使用ip命令替代)。ip: 显示或配置网络接口信息。ping: 向目标主机发送 ICMP 回显请求以测试网络连接。traceroute或tracepath: 显示到目标主机的路由路径。netstat: 显示网络连接、路由表和网络接口统计信息。wget或curl: 下载文件或内容。ssh: 安全 Shell,用于远程登录和执行命令。
这些是一些 Linux 中常用的命令,但 Linux 系统提供了更多功能丰富的命令和工具,具体使用取决于你的需求和场景。
find命令
find 命令是在 Linux 和类 Unix 系统中用于在文件系统中搜索文件和目录的工具。
它提供了广泛的搜索选项,可以根据不同的标准来定位文件和目录。以下是 find 命令的一些常见用法和选项:
基本用法:
find [path...] [expression]path: 指定要搜索的起始路径。如果未指定,则默认从当前目录开始搜索。expression: 指定搜索的条件和操作。
常用选项:
-name pattern: 根据文件名模式进行搜索。-type type: 指定要搜索的文件类型,如f表示普通文件,d表示目录等。-size [+|-]size: 根据文件大小进行搜索,+size表示大于指定大小,-size表示小于指定大小。-exec command {} \;: 对搜索到的每个文件执行指定的命令。-print: 将搜索到的文件名输出到标准输出。-delete: 删除搜索到的文件。-maxdepth level: 指定搜索的最大深度。-mindepth level: 指定搜索的最小深度。
示例:
搜索当前目录及其子目录中所有文件名以
.txt结尾的文件:```
find . -name "*.txt"
├── test-find
│ └── a
│ ├── a.txt
│ └── b
│ ├── b1.txt
│ ├── b2.txt
│ ├── b3.txt
│ ├── b4.txt
│ ├── b5.txt
│ └── c
│ ├── c1.log
│ ├── c2.log
│ ├── c3.log
│ ├── c4.log
│ ├── c5.log
│ └── d
│ └── e
├── test.txt
├── use-vim.txt
└── yuchao.txt
root@VM-8-7-ubuntu:~# find /root/test-find/ -name '*.txt'
/root/test-find/a/b/b3.txt
/root/test-find/a/b/b2.txt
/root/test-find/a/b/b4.txt
/root/test-find/a/b/b5.txt
/root/test-find/a/b/b1.txt
/root/test-find/a/a.txt
# 要你的结果,不要那么多前缀
root@VM-8-7-ubuntu:~# find ./test-find/ -name '*.txt'
./test-find/a/b/b3.txt
./test-find/a/b/b2.txt
./test-find/a/b/b4.txt
./test-find/a/b/b5.txt
./test-find/a/b/b1.txt
./test-find/a/a.txt
root@VM-8-7-ubuntu:~# find ./test-find/ -name '*.log'
./test-find/a/b/c/c4.log
./test-find/a/b/c/c2.log
./test-find/a/b/c/c5.log
./test-find/a/b/c/c1.log
./test-find/a/b/c/c3.log
```
# 找到所有目录
root@VM-8-7-ubuntu:~# find . -type d -ls
# 找到所有的txt文件,且删除
root@VM-8-7-ubuntu:~# find . -type f -name '*.txt' -delete
root@VM-8-7-ubuntu:~#
root@VM-8-7-ubuntu:~# find . -type f -name '*.txt'
```
搜索
/home目录中大小大于 1MB 的文件:```
find /home -type f -size +1M
找出大于1M的文件且统计其单位
root@VM-8-7-ubuntu:~# find /home -type f -size +1M -exec du -h {} \;
```
# 超过7天被修改的文件,超过一周了
find /var/log -mtime +7
# 正好是第7天被修改的文件
find /var/log -mtime 7
```
搜索
/usr/bin目录中名为gcc的可执行文件并打印它们的路径:root@VM-8-7-ubuntu:~# find /usr/bin -type f -name '*gcc*' /usr/bin/c99-gcc /usr/bin/x86_64-linux-gnu-gcc-11 /usr/bin/x86_64-linux-gnu-gcc-ranlib-11 /usr/bin/c89-gcc /usr/bin/x86_64-linux-gnu-gcc-nm-11 /usr/bin/x86_64-linux-gnu-gcc-ar-11
find 命令的选项非常丰富,可以根据具体的需求灵活组合使用。需要注意的是,在使用 find 命令时要谨慎,特别是在使用删除操作时,以免意外删除重要文件。建议在测试过程中先使用 -print 选项输出结果,确认结果正确后再执行删除或其他操作。
案例
当在实际工作中使用 find 命令时,可能会遇到各种不同的情况和需求。以下是一些实际工作场景下常见的 find 命令用法案例:
查找特定类型的文件:
搜索系统中所有的文本文件:
find / -type f -name "*.txt"查找并列出所有目录:
find /path/to/search -type d
根据文件大小进行搜索:
查找大于 100MB 的文件:
find / -type f -size +100M查找小于 1KB 的文件:
find / -type f -size -1k
根据文件的修改时间进行搜索:
查找最近 7 天内修改过的文件:
find / -type f -mtime -7查找修改时间在 30 天前的文件:
find / -type f -mtime +30
结合
-exec执行操作:删除所有
.tmp文件:find /path/to/search -type f -name "*.tmp" -exec rm {} \;修改所有
.txt文件的权限为只读:find /path/to/search -type f -name "*.txt" -exec chmod 644 {} \;
在特定深度范围内搜索:
只在当前目录及其子目录中搜索:
find . -maxdepth 1 -type f -name "*.txt"搜索深度为 2 的目录中的文件:
find /path/to/search -mindepth 2 -maxdepth 2 -type f
查找特定用户的文件:
查找 /home目录下所有属于 user1用户的文件:
find /home -type f -user user1
这些案例只是 find 命令在实际工作中的一些用法示例,你可以根据具体的需求和场景进一步调整和组合命令选项。
dd命令
dd 命令是一个强大的 Unix/Linux 工具,用于复制和转换文件。它通常用于复制磁盘、创建镜像、备份和恢复数据等任务。dd 命令的基本用法如下:
dd if=input_file of=output_file [options]
其中:
if=input_file: 指定输入文件的路径或者设备名。of=output_file: 指定输出文件的路径或者设备名。[options]: 可选参数,用于指定复制过程中的一些选项。
以下是一些常用的 dd 命令选项和用法示例:
复制文件:
dd if=input_file of=output_file这将从
input_file复制数据到output_file。复制设备:
dd if=/dev/sda of=/dev/sdb这将从
/dev/sda设备复制数据到/dev/sdb设备,通常用于硬盘克隆或备份。指定块大小:
dd if=input_file of=output_file bs=4K这将指定块大小为 4KB,即每次复制 4KB 的数据。
指定复制大小:
dd if=input_file of=output_file count=100这将指定只复制文件的前 100 个块。
显示进度:
dd if=input_file of=output_file status=progress这将显示复制过程的进度信息。
跳过输入文件的头部数据:
dd if=input_file of=output_file skip=10这将跳过输入文件的前 10 个块。
直到结束符为止复制:
dd if=input_file of=output_file until=end_marker这将复制输入文件直到遇到指定的结束标志符。
修改数据:
dd if=input_file of=output_file conv=ucase这将将输出文件中的所有字符转换为大写。
创建随机数据:
dd if=/dev/urandom of=random_file bs=1M count=10这将创建一个大小为 10MB 的随机数据文件。
dd 命令非常强大,但同时也很危险,因为它允许直接访问设备,并且没有很多安全检查。在使用 dd 命令时,请务必谨慎,并确保你了解命令选项的含义以及操作的后果。错误的使用可能会导致数据丢失或系统损坏。
tree命令
tree 命令用于以树状结构显示目录和文件的层次结构。它是一个非常有用的工具,可以帮助用户快速了解目录结构,并可选地显示文件的属性信息。以下是 tree 命令的基本用法和一些常用选项:
cssCopy code
tree [options] [directory]
其中 [options] 是可选参数,[directory] 是要显示树状结构的目录。如果未指定目录,则默认为当前目录。
一些常用的 tree 命令选项包括:
-a:显示所有文件和目录,包括隐藏的文件。-d:只显示目录,不显示文件。-f:以完整路径的方式显示文件名。-L level:指定要显示的目录层级深度。-l:显示文件和目录的权限、用户、组和修改日期等详细信息。-h:使用人类可读的格式显示文件大小。-p:以文件类型为基础进行排序。-u:按文件访问时间(atime)排序而不是修改时间(mtime)排序。-r:反向排序。-I pattern:排除与指定模式匹配的文件或目录。
下面是一些常用示例:
显示当前目录的树状结构:
tree显示指定目录的树状结构:
tree /path/to/directory只显示目录,不显示文件:
tree -d显示指定目录下的目录层级结构:
tree -L 2 /path/to/directory显示文件和目录的详细信息:
tree -l使用人类可读的格式显示文件大小:
tree -h排除指定模式的文件或目录:
tree -I "*.txt"
tree 命令是一个非常方便的工具,可以用于快速浏览文件系统的结构,特别是对于大型目录结构,它能够提供清晰的展示。
scp命令
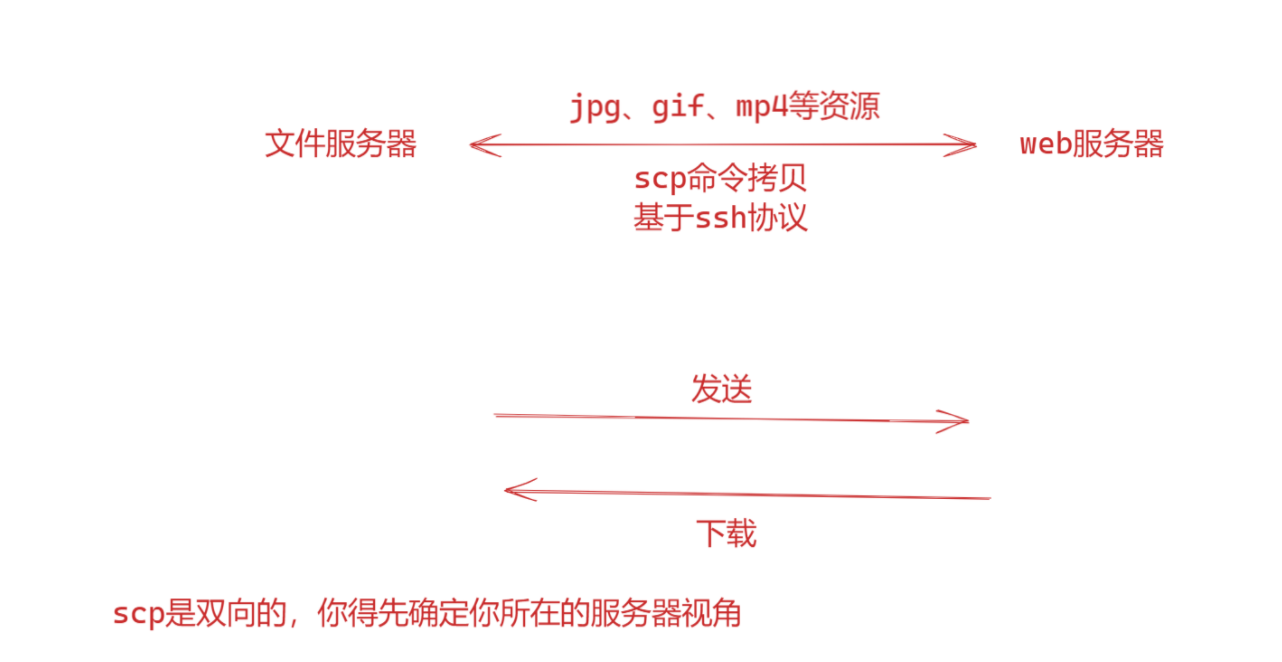
下载
A
B
机器之间的通信情况
能首发数据 前提是 网络通信ok
本地练习
A ,B 机器,在一个局域网下,互相首发数据。
# 腾讯云服务器给各位演示
于超老师的个人电脑(家庭宽带,电信,公网IP) ------(公网IP 49.232.220.205 ) 腾讯云服务器
scp(Secure Copy Protocol)命令用于在本地系统和远程系统之间进行安全的文件传输。它基于SSH协议,通过加密的方式传输文件,因此非常适合在不同主机之间安全地复制文件和目录。以下是 scp 命令的基本用法和一些常用选项:
scp [options] source destination
# 语法,案例
scp 参数 源文件 目标文件
# 拉取腾讯云服务器的 yuchao.txt文件到 本地桌面
# git bash这个终端操作
# 前提是有一个可以基于ssh登录的账户 ubuntu账户
# root用户去测试,
# 拉取远程主机的文件,到本地目录
scp ubuntu@49.232.220.205:/home/ubuntu/yuchao.txt ./Desktop/
# 发送本地文件,到远程主机,上传到服务器,不改名字
scp 参数 源文件 目标文件
$ scp ~/Desktop/yuchao.txt ubuntu@49.232.220.205:/home/ubuntu/yuchao-2.txt [11:14:50]
ubuntu@49.232.220.205's password:
yuchao.txt
# 拷贝文件夹,递归拷贝,本地的一个文件夹,全部发送给远程主机
scp -r ~/Desktop/lol ubuntu@49.232.220.205:/home/ubuntu
其中 [options] 是可选参数,source 是源文件或目录,destination 是目标路径。source 和 destination 可以是本地路径或远程路径(格式为user@host:path)。
一些常用的 scp 命令选项包括:
-r:递归复制整个目录树。-P port:指定远程主机的端口,默认为 22。-p:保持源文件的修改时间、权限和访问时间。-q:安静模式,不显示传输过程中的信息。-v:详细模式,显示传输过程中的详细信息。-C:启用压缩传输,可以加快传输速度。-i identity_file:指定身份文件(私钥文件)。-B:使用批处理模式(不提示输入密码或密钥短语)。-l limit:限制传输带宽。
下面是一些常用示例:
从本地系统复制文件到远程系统:
scp local_file remote_user@remote_host:/remote/path从远程系统复制文件到本地系统:
scp remote_user@remote_host:/remote/file /local/path递归复制整个目录树:
scp -r local_dir remote_user@remote_host:/remote/path指定远程主机的端口:
scp -P 2222 local_file remote_user@remote_host:/remote/path保持源文件的修改时间、权限和访问时间:
scp -p local_file remote_user@remote_host:/remote/path启用压缩传输:
scp -C local_file remote_user@remote_host:/remote/path指定身份文件(私钥文件):
scp -i /path/to/private_key local_file remote_user@remote_host:/remote/path
scp 命令非常实用,特别适用于需要在本地系统和远程系统之间安全传输文件的场景。
crontab
crontab 是一个用于在 Linux 和类 Unix 系统上设置定时任务的命令。它允许用户在指定的时间执行命令、脚本或程序,非常适合自动化重复性的任务。以下是 crontab 命令的基本用法和一些常用选项:
基本用法:
编辑当前用户的定时任务列表:
crontab -e列出当前用户的定时任务列表:
crontab -l删除当前用户的定时任务列表:
crontab -r
定时任务的格式:
一个典型的 crontab 记录由以下几个字段组成,用空格或制表符分隔:
* * * * * command
这五个星号表示了任务执行的时间间隔和时间点:
- 第一个星号代表分钟 (0 - 59)
- 第二个星号代表小时 (0 - 23)
- 第三个星号代表日期 (1 - 31)
- 第四个星号代表月份 (1 - 12)
- 第五个星号代表星期几 (0 - 7,0 和 7 都表示周日)
选项和示例:
每分钟执行一次命令:
* * * * * command每小时的第 30 分钟执行一次命令:
30 * * * * command每天的凌晨执行一次命令:
0 0 * * * command每周一的凌晨执行一次命令:
0 0 * * 1 command每月的第一天凌晨执行一次命令:
0 0 1 * * command每天的上午 8 点到下午 5 点,每隔半小时执行一次命令:
*/30 8-17 * * * command指定日志输出:
* * * * * command >> /path/to/logfile 2>&1在特定时间运行命令:
0 20 * * 1-5 command # 每周一至周五的晚上 8 点执行命令每 10 分钟运行一次命令:
*/10 * * * * command定时任务的特殊字符:
*:代表所有可能的值。,:用于指定多个值,如1,3,5表示 1、3 和 5。-:用于指定范围,如1-5表示 1 到 5。/:用于指定步长,如*/10表示每隔 10。@reboot:在系统启动时执行。
注意:crontab 使用的时间是系统时间,而不是本地时间。因此,要确保系统时间设置正确。
crontab 是一个非常强大的工具,可用于执行各种定时任务,如备份、日志清理、定期数据处理等。使用时需谨慎,确保定时任务不会对系统产生负面影响。
时间日期命令
在 Ubuntu 中,你可以使用以下命令来管理时间和日期:
date:
date命令用于显示当前系统日期和时间,或者根据指定格式显示日期和时间。datetimedatectl:
timedatectl命令用于控制系统时间和日期,以及时区设置。显示系统时间和日期:
timedatectl显示系统时区:
timedatectl | grep Timezone设置时区:
sudo timedatectl set-timezone your_time_zone
其中
your_time_zone是你希望设置的时区名称,例如Asia/Shanghai。hwclock:
hwclock命令用于显示或设置硬件时钟(即 BIOS 中的时钟)的时间。显示硬件时钟时间:
sudo hwclock将系统时间写入硬件时钟:
sudo hwclock --systohc
ntpdate:
ntpdate命令用于通过 NTP 协议从 NTP 服务器同步系统时间。同步系统时间:
sudo ntpdate ntp_server
其中
ntp_server是你希望同步时间的 NTP 服务器地址。tzselect:
tzselect命令用于交互式地选择时区。tzselectdate命令的格式化选项:
date命令支持许多格式选项,例如:%Y:四位数年份。%m:月份(01-12)。%d:月中的第几天(01-31)。%H:小时(00-23)。%M:分钟(00-59)。%S:秒(00-59)。 你可以结合这些选项以自定义日期和时间的格式,例如:
date +"%Y-%m-%d %H:%M:%S"
这些命令可以帮助你在 Ubuntu 系统上管理时间和日期。
源码编译
很简单
源码编译是将软件源代码转换成可执行程序的过程。
一堆代码文件,英文字母
得通过程序,软件转换过程
转换为计算机,cpu能认识010101010
就有了作用,就可以执行了。
通常情况下,你会在 Linux 系统上遇到需要从源代码编译安装软件的情况,这可能是因为你需要定制特定的功能、优化性能,或者是某些软件包在官方仓库中不可用。下面是源码编译的基本步骤和详细解释:
基本步骤:
获取源代码:
- 下载源代码压缩包,通常以
.tar.gz、.tar.bz2、.tar.xz等格式提供。 - 从版本控制系统(如 Git、SVN)中获取源代码。
- 下载源代码压缩包,通常以
解压源代码:
tar -xf source_code.tar.gz进入源代码目录:
cd source_code_directory配置编译选项: 通常需要运行
./configure脚本来配置软件的编译选项,该脚本会检查系统环境并生成Makefile。# 程序员,sh脚本 ,直接运行它 # 配置,定义软件该如何编译,以及给软件拓展一些功能 ./configure [options]编译: 运行
make命令来编译源代码。make # 自动读取makefile,调用系统,gcc编译器,linux中编译软件,大多数是指c程序 # jar包,java系统 # golang 编译安装(可选): 如果需要,可以运行
make install命令将编译好的程序安装到系统中。sudo make install
详细解释:
- 配置编译选项:
./configure脚本通常会检查系统环境和依赖关系,并根据检测结果生成 Makefile。它可以接受一些选项来定制编译过程,例如指定安装目录、启用或禁用某些功能等。- web server软件,系统有ssl perl zlib库
- 常见的选项包括:
--prefix=PREFIX:指定安装目录。--enable-feature:启用某个功能。--disable-feature:禁用某个功能。- 更多选项可以通过运行
./configure --help查看。
- 编译:
make命令根据 Makefile 文件编译源代码,它会执行 Makefile 中定义的编译规则来生成目标文件和可执行文件。
- 安装:
make install命令将编译好的程序、库文件以及其他必要的文件复制到系统中。需要注意的是,运行make install需要超级用户权限,因此通常需要使用sudo命令来执行。
这些是源码编译的基本步骤和详细解释。在进行源码编译时,需要留意软件的文档或官方网站上提供的指导,以确保正确配置和编译软件。
编译相关工具
在 Ubuntu 中进行源码编译时,你通常需要安装一些基本的开发工具和依赖项,以确保源码可以成功编译。以下是一些常见的依赖项:
编译工具:
build-essential:包含了一些基本的编译工具,如编译器(gcc、g++)、make 工具等。
sudo apt update sudo apt install build-essential
自动配置工具:
autoconf:用于自动生成软件的配置脚本。
sudo apt install autoconfautomake:用于自动生成 Makefile。
sudo apt install automakelibtool:用于管理动态库的工具。
sudo apt install libtool
其他常见依赖项:
pkg-config:用于检查已安装的库的版本信息。
sudo apt install pkg-configcmake:用于跨平台的构建系统,通常用于替代 autoconf 和 automake。
sudo apt install cmake
特定软件包的依赖项:
- 某些软件包可能需要特定的依赖项,例如开发库、头文件等。你可以查看软件包的文档或官方网站来获取详细的依赖项信息,并根据需要安装这些依赖项。
在安装完上述基本依赖项后,你应该能够进行大多数常见的源码编译工作了。但请注意,具体的依赖项可能因不同的软件而有所不同,因此在编译特定软件之前,最好先查阅该软件的文档或官方网站,以了解其详细的编译依赖项。
apt install autoconf automake libtool pkg-config cmake -y
源码编译屏保程序
nginx,python3,xxx
骇客帝国,c程序开发屏保程序
libncurses-dev 是针对 ncurses 库的开发包,在 Ubuntu 中它提供了用于开发 ncurses 应用程序的头文件和静态库。ncurses 是一个用于控制终端的库,允许程序创建复杂的文本用户界面(TUI)。它提供了一系列函数和数据结构,使程序能够在终端上进行光标移动、颜色控制、屏幕刷新等操作,从而创建出像图形界面一样的用户交互体验。
在开发需要使用 ncurses 库的程序时,通常需要包含 ncurses.h 头文件,并链接 libncurses 静态库。安装 libncurses-dev 包可以方便地获取这些开发所需的文件,使得编写和编译 ncurses 应用程序更加便捷。
# 安装一些前置底层工具
# 这些经验哪来的,都是前人踩坑,遇见报错,google查资料解决,找到的办法
apt install build-essential autoconf automake libtool pkg-config cmake
libncurses-dev -y
apt install wget -y
wget http://jaist.dl.sourceforge.net/project/cmatrix/cmatrix/1.2a/cmatrix-1.2a.tar.gz
tar -xf cmatrix-1.2a.tar.gz
cd /opt/cmatrix-1.2a
# 告诉编译器,我要吧软件安装到这个路径
root@yuchao-linux-2024:/opt/cmatrix-1.2a# ./configure --prefix=/opt/cmatrix/
# 如果编译报错,缺少
cmatrix.c:37:10: fatal error: curses.h: No such file or directory
# 只需要安装如下命令即可
apt install libncurses-dev -y
# 再次make即可
make
make install
# 进入你指定的安装路径,看看是否生成二进制命令
root@yuchao-linux-2024:/opt/cmatrix-1.2a# cd /opt/cmatrix/bin/
root@VM-8-7-ubuntu:/opt/cmatrix# ls
bin man
# 至此源码编译成功
root@VM-8-7-ubuntu:/opt/cmatrix/bin# ls /opt/cmatrix/bin/cmatrix
/opt/cmatrix/bin/cmatrix
# 基于如下源码文件生成的
root@VM-8-7-ubuntu:/opt/cmatrix/bin# ls /opt/cmatrix-1.2a
acconfig.h cmatrix cmatrix.spec config.h config.sub INSTALL Makefile.in mkinstalldirs stamp-h
aclocal.m4 cmatrix.1 cmatrix.spec.in config.h.in configure install-sh matrix.fnt mtx.pcf stamp-h.in
AUTHORS cmatrix.c config.cache config.log configure.in Makefile matrix.psf.gz NEWS TODO
ChangeLog cmatrix.o config.guess config.status COPYING Makefile.am missing README
root@VM-8-7-ubuntu:/opt/cmatrix/bin#
环境变量PATH
环境变量 PATH 是一个在 Unix 和类 Unix 系统中非常重要的环境变量,它指定了系统在搜索可执行文件时应该查找的路径列表。当你在命令行中输入一个命令时,系统会按照 PATH 中指定的顺序在这些路径中搜索对应的可执行文件,并执行找到的第一个匹配项。
root@VM-8-7-ubuntu:/opt/cmatrix/bin# name="超哥牛皮"
root@VM-8-7-ubuntu:/opt/cmatrix/bin#
root@VM-8-7-ubuntu:/opt/cmatrix/bin#
root@VM-8-7-ubuntu:/opt/cmatrix/bin# echo ${name}
超哥牛皮
root@VM-8-7-ubuntu:/opt/cmatrix/bin#
root@VM-8-7-ubuntu:/opt/cmatrix/bin#
root@VM-8-7-ubuntu:/opt/cmatrix/bin# name="超哥牛啥呀牛 你个小子"
root@VM-8-7-ubuntu:/opt/cmatrix/bin#
root@VM-8-7-ubuntu:/opt/cmatrix/bin# echo ${name}
超哥牛啥呀牛 你个小子
PATH 的结构:
PATH是一个由冒号:分隔的路径列表,每个路径对应一个目录。- 通常情况下,
PATH的值以/bin、/usr/bin、/usr/local/bin等标准系统路径开始。 - 你也可以将自定义的路径添加到
PATH中,以便系统可以在这些路径中搜索你自己安装的可执行文件。
PATH 的作用:
- 当你在命令行中输入一个命令时,系统会从
PATH中列出的每个目录中依次查找这个命令对应的可执行文件,直到找到第一个匹配的文件为止。 - 如果找不到对应的可执行文件,系统会提示“命令未找到”的错误。
修改 PATH:
你可以通过直接修改环境变量的方式来修改
PATH。在 Bash shell 中,可以使用 export命令来设置 PATH,例如:
export PATH="/custom/directory:$PATH"这样会将 /custom/directory 添加到 PATH
的开头,使得系统优先搜索该目录中的可执行文件。
为什么 PATH 很重要?
PATH的设置直接影响了系统中可执行文件的搜索顺序,从而决定了你在命令行中输入命令时系统会执行哪个程序。- 通过合理设置
PATH,你可以方便地管理系统中的可执行文件,使得你的自定义程序和系统自带程序能够被方便地找到和执行。
总之,PATH 是一个非常重要的环境变量,在使用命令行进行操作时起着至关重要的作用。因此,合理设置和管理 PATH 是系统管理和开发工作中的基本操作之一。
永久修改添加cmatrix环境变量
root@yuchao-linux-2024:/opt/cmatrix/bin# tail -1 ~/.bashrc
export PATH=$PATH:/opt/cmatrix/bin
root@yuchao-linux-2024:/opt/cmatrix/bin#
root@yuchao-linux-2024:/opt/cmatrix/bin# source ~/.bashrc
root@yuchao-linux-2024:/opt/cmatrix/bin#
root@yuchao-linux-2024:/opt/cmatrix/bin# cd
root@yuchao-linux-2024:~#
root@yuchao-linux-2024:~# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin:/opt/cmatrix/bin
root@yuchao-linux-2024:~#
root@yuchao-linux-2024:~#
root@yuchao-linux-2024:~# which cmatrix
/usr/bin/cmatrix
root@yuchao-linux-2024:~#
卸载源码编译
要卸载通过源码编译安装的软件,通常需要手动删除已安装的文件和目录,因为源码安装通常不会创建包管理器可识别的安装记录。以下是一般的卸载步骤:
找到安装目录: 首先,你需要找到源码编译安装的软件所在的安装目录。通常情况下,这个目录会由你在编译时指定的
--prefix选项决定,默认情况下可能是/usr/local或者/opt目录下的子目录。删除安装目录: 使用
rm -rf命令删除安装目录及其子目录和文件。sudo rm -rf /path/to/installation_directory删除可能存在的其他文件: 如果在安装过程中创建了其他文件或目录,也需要一并删除。
清理环境变量(可选): 如果在安装过程中添加了环境变量,例如
PATH,可能需要手动删除或修改这些环境变量的设置。卸载相关软件包(可选): 如果你在编译安装前安装了相关的开发工具或库,可以使用包管理器卸载这些软件包。这可以确保你的系统保持干净。
需要注意的是,这种方法可能不是最优雅和最安全的,因为它直接删除了文件和目录而没有记录。如果你还记得编译安装时所用的 Makefile,你也可以尝试运行 make uninstall 命令,这样会尝试删除安装过程中创建的文件和目录。但并不是所有的软件都提供了这个功能,所以这个方法并不总是可行的。
如果你担心删除过程中会删除到其他重要文件,建议提前备份重要数据或者确认安装目录下只包含你想删除的软件。
作业:编译安装Python3
2024年,ai热火,C C++
Python 二次开发
开发语言,自动化,运维,测开,AI类接口开发,python3 环境
有几种情况下可能会选择编译安装 Python 3:
- 最新版本需求:Linux 发行版通常会提供稳定版本的 Python,但可能不会及时更新到最新版本。如果你需要使用 Python 的最新功能或修复了的 bug,可能会选择编译安装最新版本的 Python。
- 特定配置需求:某些场景下,你可能需要自定义 Python 的配置选项,例如启用或禁用某些模块、调整编译参数等。通过编译安装,你可以自由地配置 Python。
- 虚拟环境需求:如果你希望在用户级别而不是系统级别上安装 Python,可以编译安装到用户的主目录下,或者使用虚拟环境管理多个 Python 版本。
- 依赖管理:有时,特定的应用程序或库可能需要特定版本的 Python,而不是系统中默认的版本。在这种情况下,编译安装可以让你安装所需的 Python 版本,并在不影响系统的情况下管理这些依赖关系。
- 自定义路径:默认情况下,系统包管理器安装的 Python 可能会将可执行文件安装到标准路径下,而你可能希望将 Python 安装到其他路径,或者配置其他路径作为 Python 的安装路径。通过编译安装,你可以自由选择安装路径。
总之,编译安装 Python 主要是为了获得更大的灵活性和控制权,以满足特定的需求和配置。虽然编译安装需要一些额外的工作和管理,但它为用户提供了更多的选择和定制的可能性。
root@yuchao-linux-2024:~# python3
python3 python3.10 python3.10-config python3-config
root@yuchao-linux-2024:~# python3 -V
Python 3.10.12
要求,安装python3.12.2版本,且配置好PATH环境变量。
wget https://www.python.org/ftp/python/3.12.2/Python-3.12.2.tar.xz
wget https://www.python.org/ftp/python/3.12.2/Python-3.12.2.tgz
# 注意校验文件完整性
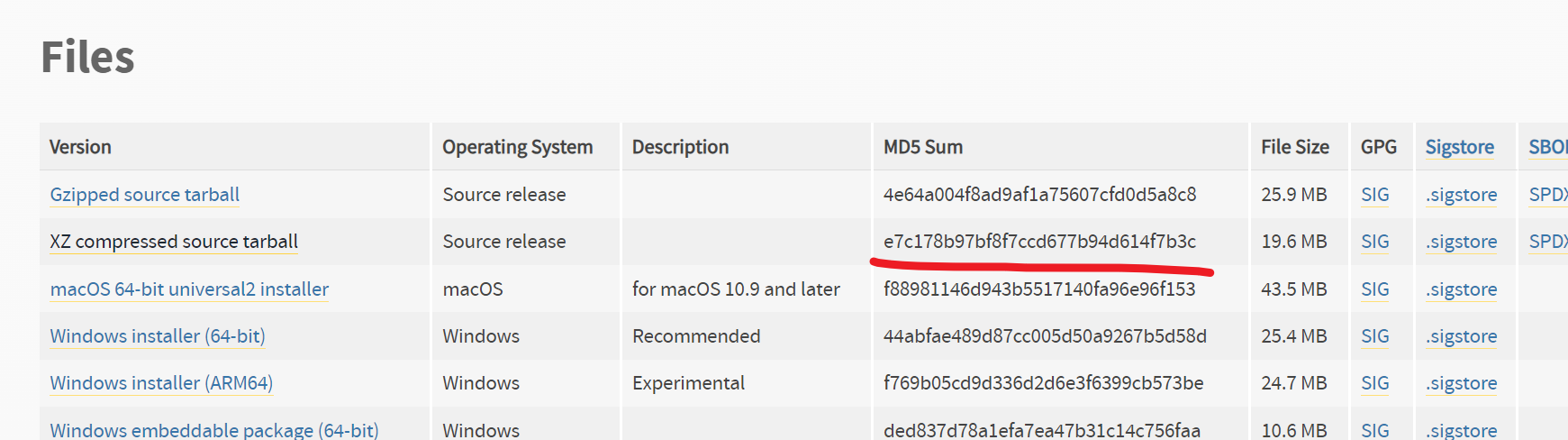
root@yuchao-linux-2024:/opt# md5sum Python-3.12.2.tar.xz
69b6dbd4672b4666a6073628e474a65a Python-3.12.2.tar.xz
make命令
make 和 make install 是在编译和安装软件时使用的两个常见命令。
- make:
make是一个用于自动化构建的命令,在编译源代码时特别有用。- 当你运行
make命令时,它会检查当前目录中的 Makefile 文件,并按照其中的规则来执行编译任务。Makefile 中包含了构建软件所需的命令和依赖关系。 make命令会执行 Makefile 中默认的目标(通常是编译源代码),但你也可以指定其他目标来执行特定的任务。
- make install:
make install命令用于将已经编译好的软件安装到系统中。- 它会将编译后的文件复制到指定位置,通常是系统的标准路径中(例如
/usr/local/bin)。 make install通常会根据 Makefile 中指定的安装路径将文件复制到合适的位置,但有时也可以通过命令行参数来指定安装路径。
综上所述,运行 make && make install 将首先编译源代码,然后将编译好的软件安装到系统中。
tar -xf Python-3.12.2.tar.xz
./configure --prefix=/usr/local/python3.12
make && make install
root@yuchao-linux-2024:~# tail -1 ~/.bashrc
export PATH=$PATH:/opt/cmatrix/bin:/usr/local/python3.12/bin
root@yuchao-linux-2024:~# source ~/.bashrc
root@yuchao-linux-2024:~# python3
python3 python3.10 python3.10-config python3.12 python3.12-config python3-config
root@yuchao-linux-2024:~# python3.12
Python 3.12.2 (main, Mar 23 2024, 15:20:15) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
root@yuchao-linux-2024:~# python3.12
Python 3.12.2 (main, Mar 23 2024, 15:20:15) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> asdasd^[[C^[[D^[[C^[[C^[[A^H^H^[[1;5D^[[1;5D^[[1;5C^[[1;5C^C
KeyboardInterrupt
>>> import readline
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'readline'
>>>
上述步骤,你已经成功编译安装好了python3.12.2
接下来是给各位演示一个生产下常见需求,如解释器,缺少某驱动,需要你重新安装。
编译的软件,如缺少功能
删除旧软件安装系统所需底层库,redline驱动重新编译安装python3,自动configure检查环境,添加新功能- 成功修复。python3.12.2
修复libreadline-dev驱动
libreadline-dev是用于开发的 GNU Readline 库的 Debian/Ubuntu 包。这个包提供了 GNU Readline 库的头文件和静态库,使开发者能够编写依赖于 Readline 功能的程序。以下是
libreadline-dev包中包含的主要内容:
- Readline 头文件:包含了编程时需要包含的头文件,通常是
readline/readline.h和readline/history.h。这些头文件包含了对 Readline 库功能的声明和定义。- Readline 静态库:静态库文件 (
libreadline.a) 包含了编译链接到你的程序中的 GNU Readline 库的实现。当你需要在程序编译期间链接 Readline 库时,你会使用这个静态库。通过安装
libreadline-dev,开发者可以利用 GNU Readline 库的功能,如命令行编辑、自动补全和历史记录管理等,来增强他们的命令行程序。这个库特别适用于开发需要用户交互的命令行应用程序,例如 Shell、交互式解释器或任何需要命令行界面的程序。
总之,
libreadline-dev是一个方便的开发工具包,使开发者能够轻松地利用 GNU Readline 库的功能,并在他们的应用程序中实现强大的命令行编辑和历史记录管理功能。
root@yuchao-linux-2024:~# rm -rf /usr/local/python3.12/
root@yuchao-linux-2024:~#
root@yuchao-linux-2024:~# sudo apt install libreadline-dev -y
如果你使用 /usr/local/python3.12/ 编译并安装了 Python 3.12,但发现缺少了 readline 模块,你可以按照以下步骤解决:
- 安装 readline 库的开发包:首先,你需要确保你的系统上安装了 readline 库的开发包,因为 Python 的 readline 模块依赖于 readline 库。你可以使用以下命令安装:
sudo apt install libreadline-dev
- 重新编译 Python:接下来,你需要重新编译 Python,但这次需要确保在编译之前正确配置。在编译之前,进入 Python 的源代码目录,运行
configure脚本并确保 readline 库的路径被正确检测到。你可以使用以下命令:
cd /path/to/Python/source
./configure --with-ensurepip=install --prefix=/usr/local/python3.12/
--enable-optimizations
make && make install
--with-ensurepip=install:这个选项告诉 Python 在编译时包含 ensurepip 模块,并在安装时安装 pip 包管理器。ensurepip 模块是一个标准库模块,用于确保 pip 在 Python 安装中可用。通过将此选项设置为 install,你可以确保在安装 Python 后,pip 会自动安装。
--enable-optimizations:这个选项启用了编译时的一些优化,以提高 Python 解释器的性能。
这些优化包括启用额外的 C 编译器标志,以及对解释器执行的一些优化。
启用此选项会使编译过程更慢,但最终的 Python 解释器性能会得到改善。
综上所述,运行 ./configure --with-ensurepip=install --enable-optimizations 这个命令告诉 Python 在编译时包含 ensurepip 模块,并在安装时安装 pip,同时也启用了一些编译时的优化,以提高 Python 解释器的性能。
确保在运行 configure 时,它能够检测到 readline 库。如果 readline 库位于非标准位置,你可能需要指定 --with-readline 选项并提供 readline 库的路径。
- 编译并安装 Python:运行
make编译 Python,并运行make install安装它。这会将包括 readline 模块在内的所有标准库和模块安装到你的/usr/local/python3.12/目录中。确保你有足够的权限来安装到/usr/local目录。
make && make install
- 验证 readline 模块:完成安装后,验证 readline 模块是否正确安装。你可以运行 Python 解释器,并尝试导入 readline 模块:
/usr/local/python3.12/bin/python3.12
在 Python 解释器中执行:
import readline
如果没有错误,则表示 readline 模块已成功导入,现在可以在 Python 中使用了。
通过这些步骤,你应该能够正确编译并安装包括 readline 模块在内的 Python 3.12 版本。
不要修改默认python3命令
在某些情况下,你可以修改系统自带的Python 3,但这通常不是一个好主意。篡改系统自带的Python 3 可能会导致系统和其他软件的不稳定性或不可预测的行为。此外,如果你不小心篡改了Python 3 的关键部分,可能会导致系统无法正常工作。
相反,推荐的做法是在系统中安装另一个版本的Python,例如通过源代码编译的方式或使用包管理器(如apt、yum、pip等)。这样做可以避免破坏系统自带的Python,同时允许你在不影响系统稳定性的情况下使用其他Python版本。
如果你想要在系统中使用其他版本的Python,可以按照以下步骤操作:
- 安装你想要使用的Python版本到系统中。
- 使用适当的命令(例如
python3.12)来调用新安装的Python版本,以区分系统自带的Python和新安装的版本。 - 避免修改系统自带的Python或其相关文件,以确保系统的稳定性和可维护性。
在使用新安装的Python版本时,请确保在使用之前进行充分测试,并注意可能出现的兼容性问题。
在Ubuntu系统中,许多系统软件和工具都依赖于Python 3。这些软件和工具可能使用Python 3来执行各种任务,例如配置管理、自动化、系统管理等。以下是一些通常依赖于系统默认的Python 3的软件和工具:
- apt/apt-get:Ubuntu的包管理器及其相关工具通常会使用Python脚本来执行包的安装、更新和卸载等操作。
- systemd:systemd服务管理器可能使用Python 3来执行一些服务配置和管理任务。
- GNOME桌面环境及其应用程序:许多GNOME桌面环境和应用程序(如Nautilus文件管理器)使用Python 3编写的插件和脚本。
- NetworkManager:Ubuntu中的网络管理器通常使用Python 3来执行网络配置和管理任务。
- Ubuntu系统配置工具:一些系统配置工具(例如系统设置)可能使用Python 3来执行配置任务。
- 系统脚本和工具:许多系统级别的脚本和工具可能使用Python 3来执行系统管理和配置任务。
这只是一些使用Python 3的示例,并不是全部。Python 3在Ubuntu系统中被广泛使用,因此有很多软件和工具都可能依赖于它。
root@yuchao-linux-2024:~# dpkg -l |grep python3 |head
ii libpython3-dev:amd64 3.10.4-0ubuntu2 amd64 header files and a static library for Python (default)
ii libpython3-stdlib:amd64 3.10.4-0ubuntu2 amd64 interactive high-level object-oriented language (default python3 version)
ii libpython3.10:amd64 3.10.12-1~22.04.3 amd64 Shared Python runtime library (version 3.10)
ii libpython3.10-dev:amd64 3.10.12-1~22.04.3 amd64 Header files and a static library for Python (v3.10)
ii libpython3.10-minimal:amd64 3.10.12-1~22.04.3 amd64 Minimal subset of the Python language (version 3.10)
ii libpython3.10-stdlib:amd64 3.10.12-1~22.04.3 amd64 Interactive high-level object-oriented language (standard library, version 3.10)
ii python3 3.10.4-0ubuntu2 amd64 interactive high-level object-oriented language (default python3 version)
ii python3-apport 2.20.11-0ubuntu82.5 all Python 3 library for Apport crash report handling
ii python3-apt 2.3.0ubuntu2 amd64 Python 3 interface to libapt-pkg
ii python3-attr 21.2.0-1 all Attributes without boilerplate (Python 3)
root@yuchao-linux-2024:~#
md5sum
md5sum 是一个用于计算文件 MD5 摘要的命令。MD5(Message-Digest Algorithm 5)是一种常用的哈希函数,它将任意长度的数据映射为固定长度的散列值,通常是一个 128 位的十六进制数字。
在使用 md5sum 命令时,它会读取指定文件的内容,并计算出该文件的 MD5 值。这个值通常被称为文件的 MD5 摘要或 MD5 校验和,它是由文件的内容决定的,即使文件名不同、路径不同,只要文件内容一致,其 MD5 值也应该一致。
在你提供的例子中,md5sum Python-3.12.2.tar.xz 表示计算名为 Python-3.12.2.tar.xz 的文件的 MD5 摘要。计算完成后,它会输出一个 128 位的十六进制数字作为结果。例如,你提供的结果 69b6dbd4672b4666a6073628e474a65a 就是该文件的 MD5 摘要。
MD5 摘要通常用于验证文件的完整性,例如在下载文件时,你可以计算文件的 MD5 摘要,并与官方提供的 MD5 摘要进行比较,以确保文件在传输过程中没有被篡改。
root@yuchao-linux-2024:/opt# md5sum Python-3.12.2.tar.xz
e7c178b97bf8f7ccd677b94d614f7b3c Python-3.12.2.tar.xz
root@yuchao-linux-2024:/opt# ll -h Python-3.12.2.tar.xz
-rw-r--r-- 1 root root 20M Mar 23 15:14 Python-3.12.2.tar.xz