linux程序运行管理
要学习如何管理在Linux上运行的程序,您可能需要学习以下内容:
- 进程管理:了解如何查看正在运行的进程,以及如何启动、停止和管理进程。
- 服务管理:学习如何使用系统服务管理工具(如systemd、SysVinit等)启动、停止和管理后台服务。
- 日志管理:了解如何查看和管理系统日志,以便跟踪程序运行时的问题和事件。
- 资源监控:学习如何使用工具(如top、htop、ps等)监控系统资源的使用情况,以及如何优化资源利用。
- 权限管理:理解用户和组的概念,学习如何管理文件和进程的权限,以确保安全性和隔离性。
- 任务调度:了解如何使用cron和at等工具来定时执行任务,如备份、日志清理等。
- 软件包管理:熟悉Linux发行版的软件包管理系统,如apt、yum/dnf等,以及如何安装、更新和删除软件包。
- 网络配置:了解如何配置网络设置,以确保程序可以正确访问网络资源。
这些是管理Linux程序运行所需的基本技能。深入学习这些主题将有助于您更好地管理和维护Linux系统中的应用程序。
windows资源管理器
在运维的日常工作中,监视系统的运行状况是每天例行的工作,一个服务器的健康,从主要的几个资源使用率上,就可以得出结论,比如CPU使用率、内存使用率,磁盘使用率。
在 Windows 中我们可以很直观的使用"任务管理器"来进行进程管理,了解系统的运行状态
通常,使用"任务管理器"主要有 3 个目的:
- 利用"应用程序"和"进程"标签来査看系统中到底运行了哪些程序和进程;
- 利用"性能"和"用户"标签来判断服务器的健康状态;
- 在"应用程序"和"进程"标签中强制中止任务和进程;
查看windows的进程信息
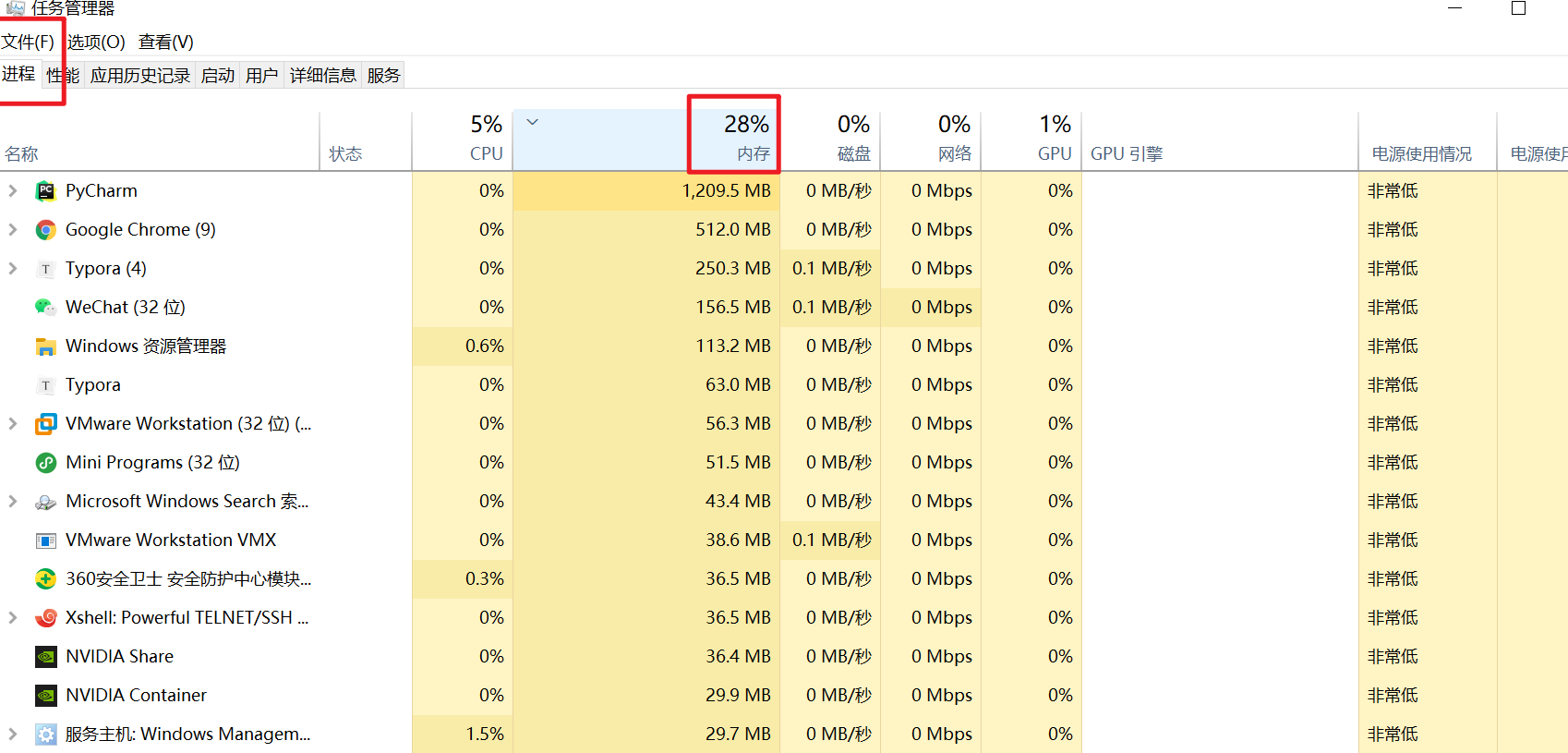
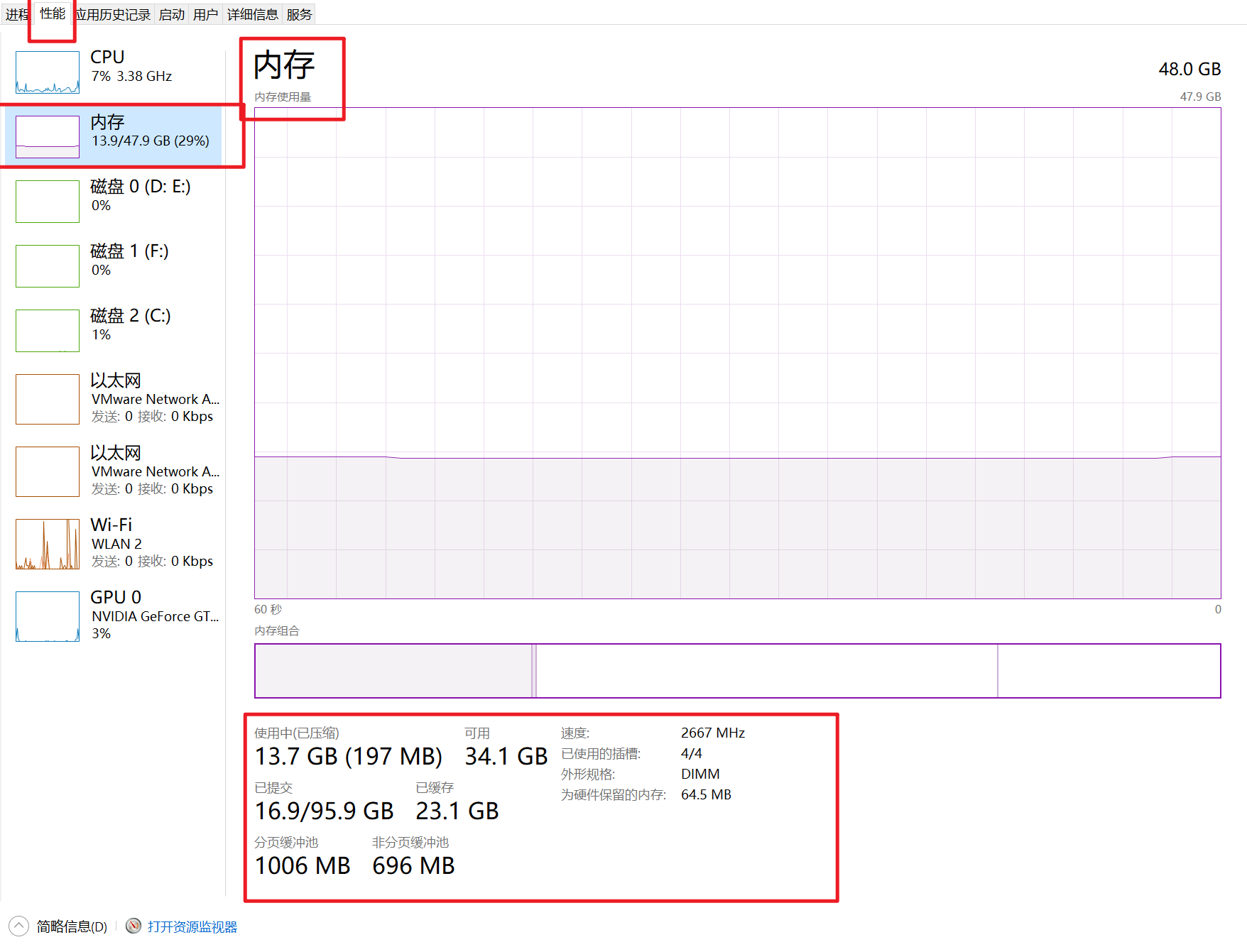
查看内存使用率,内存是系统及其重要的一个资源,内存大小,基本上决定了你电脑能打开多少个应用程序,所以你想同时听课、写代码、学于超老师的linux课,做笔记,聊微信,这么多事,需要你的内存足够大,打得开这么多软件。
否则就会出现,卡死,内存不足,无法运行软件。
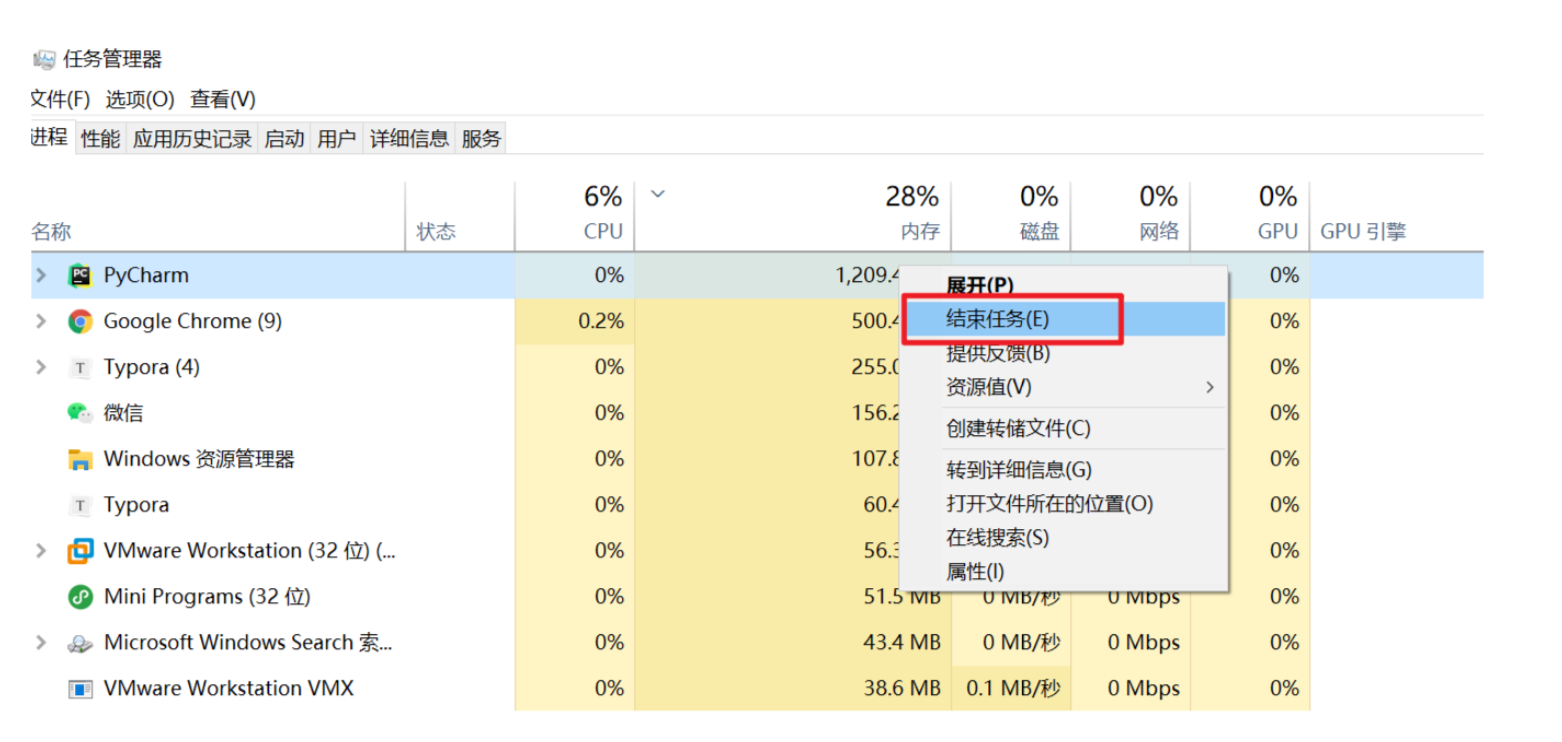
我们也可以通过资源管理器,找到很占资源的应用,关闭它
当然这是windows的用法,linux可不会提供这个画面给你点点点,基本上使用命令来进行进程管理
上述一样的操作,linux就得用命令行了。
但是进程管理的目的,都是一样
- 查看系统中运行的程序,及其程序信息
- 查看该程序的资源使用率,判断机器健康,肯定是资源用的越多,机器负担越大,前面超哥讲过,计算机硬件好比人类的身体,你的大脑负担越重,眼睛负担越重,人的压力也就越大,甚至累倒。
- 终止不需要的程序
对于新手可能觉得windows的进程管理,更直白,更好看,但是如果让你管理多个进程,自动化管理进程的启动、结束,重启,那么图形化就显得费劲了,因此linux果然是适合专业性IT人才使用的,更为高效。
linux资源管理器
linux中对需要运维去管理、去查看的资源信息,如下
- 内存资源、使用率
- free命令
- 磁盘资源、使用率
- df
- CPU资源、使用率
- top
- htop
- glances
- 进程资源、使用率
- ps
- pstree
- pidof
- 网络资源、使用率
- Iftop
- 所有资源的整体查看命令
- top
- glances
- htop
什么是进程
计算机核心是CPU,承担机器的计算任务,好比是一座工厂,时刻在运行着。

一个工厂(计算机),可以有多个车间,同时在工作。(计算机有多个进程,同时在运行)

进程是正在执行的一个程序或命令,每个进程都是一个运行的实体,并占用一定的系统资源。
程序是人使用计算机语言编写的可以实现特定目标或解决特定问题的代码集合。
简单来说,程序是人使用计算机语言编写的,可以实现一定功能,并且可以执行的代码集合。
进程是正在计算机执行中的程序。
举例:谷歌浏览器是一个程序,当我们打开谷歌浏览器,就会在系统中看到一个浏览器的进程,当程序被执行时,程序的代码都会被加载入内存,操作系统给这个进程分配一个 ID,称为 PID(进程 ID)。
我们打开多个谷歌浏览器,就有多个浏览器子进程,但是这些进程使用的程序,都是chrome。
进程、程序的关系
- 开发把代码写好了,打个压缩包给你,还未运行的时候,这就是个静态、程序源代码,程序是数据和指令的集合。
- 当运维将开发的代码运行起来之后,就称之为进程(机器上一个在运行的程序)
- 程序运行时,系统为了清晰的标记每一个进程,为其分配了PID、运行的用户、内存、CPU等使用情况。
在Linux系统中,进程是程序的执行实例。当您启动一个程序时,操作系统会为该程序创建一个进程,该进程包含了程序的代码、数据和运行时环境。进程是操作系统进行任务调度和资源分配的基本单位。
一个程序可以对应多个进程的情况。例如,如果您同时启动了两个终端窗口,并在每个终端窗口中运行了一个命令行程序,那么每个命令行程序都将有自己的进程。
进程可以相互影响和通信。例如,一个进程可以通过管道(pipe)、信号(signal)或共享内存(shared memory)等方式与另一个进程通信。进程之间的通信可以用于实现各种功能,如进程间的数据传输、同步和协作等。
进程、线程、协程
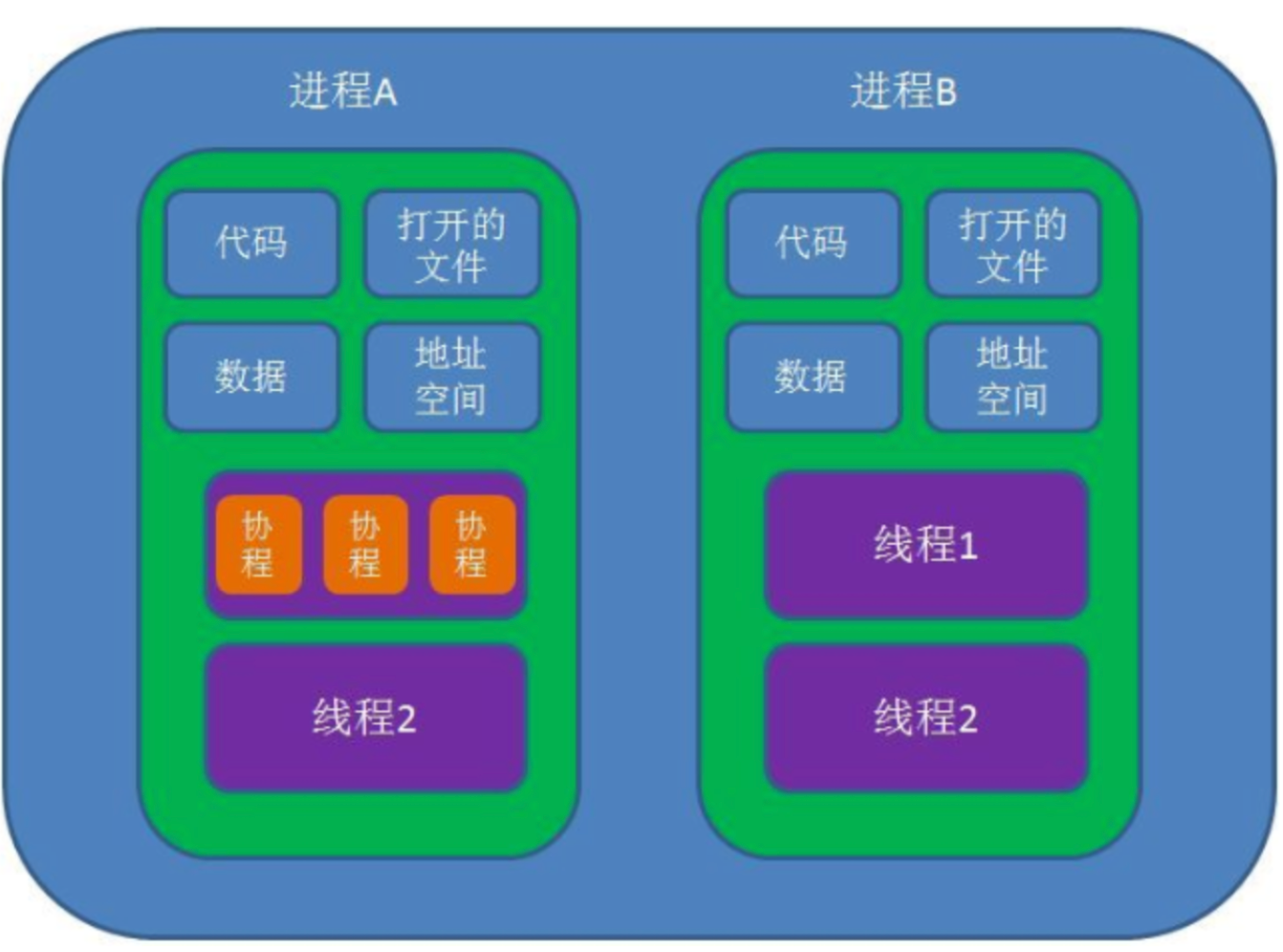
进程、线程和协程都是计算机编程中用于实现并发执行的概念,它们在实现方式和使用场景上有所不同。
- 进程(Process):进程是程序的执行实例,是操作系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间,包含了程序的代码、数据和运行时环境。进程之间通常是相互独立的,每个进程都有自己的地址空间,进程间通信需要通过特定的机制来实现,如管道、信号、消息队列等。
- 线程(Thread):线程是进程中的一个执行单元,一个进程可以包含多个线程。同一进程中的多个线程共享相同的地址空间和其他资源,包括打开的文件、信号处理器和进程状态等。线程间的通信相对容易,可以直接读写共享变量,但也需要注意线程安全性。
- 协程(Coroutine):协程是一种轻量级的线程,它不是由操作系统内核来管理,而是由程序员在用户空间自行管理。协程可以在同一个线程中实现多个执行线路,实现多个任务的协作式并发。协程通常比线程更高效,因为不涉及内核切换和资源分配。
总的来说,进程提供了最强的隔离性,线程可以更方便地共享资源和通信,而协程则提供了更高效的并发执行方式。不同的情况下,可以选择合适的并发模型来实现程序的需求。
进程fork
1.我们的操作系统都是一堆进程而已,系统运行时,就产生了0号进程,然后其他进程都是0号进程创建的子进程。
2.linux启动之后,第一个进程就是PID为0,然后通过0号进程fork()出其他的进程。
3.操作系统的运行,就是不断的创建进程、以及销毁进程。
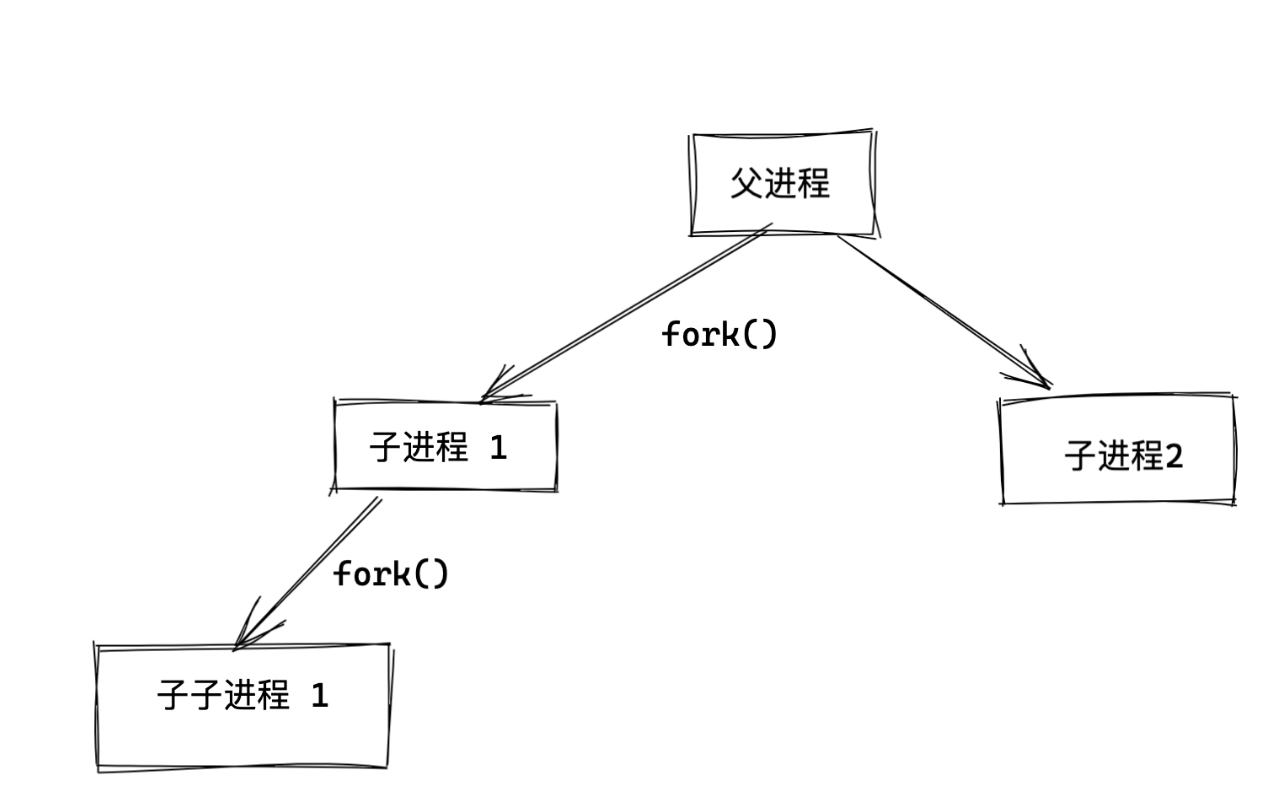
在Linux中,fork() 系统调用用于创建一个新的进程,新进程是调用进程的一个副本,但具有自己独立的内存空间和进程标识符(PID)。fork() 调用后会返回两次,一次在父进程中,一次在子进程中。在父进程中,fork() 返回子进程的 PID,而在子进程中,fork() 返回 0。
具体来说,fork() 调用会复制调用进程的地址空间(包括代码、数据和堆栈),并创建一个新的进程。父进程和子进程将在 fork() 调用后并发执行相同的程序代码,但是由于每个进程有自己的内存空间,它们可以独立地修改自己的数据而不会影响到对方。
fork() 的典型用法是在父进程中创建子进程,然后在子进程中调用 exec() 系列函数来加载并执行新的程序。这样可以实现程序的替换,子进程可以执行不同的程序,而父进程可以继续执行原来的程序或者等待子进程结束。
需要注意的是,fork() 创建的子进程是一个完整的新进程,但是它会继承父进程的文件描述符、信号处理器等状态,需要根据具体情况进行适当的处理。
[root@yuchao-linux01 ~]# ps -ef |head -5
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 12:33 ? 00:00:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0 0 12:33 ? 00:00:00 [kthreadd]
root 3 2 0 12:33 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 12:33 ? 00:00:00 [kworker/0:0H]
孤儿进程
1.当父亲进程挂了,导致儿子进程成了孤儿,甚至是一个、或者多个孤儿进程。
2.孤儿进程会被系统的1号进程收养,并且有1号进程来回收,处理这些孤儿进程。
3.孤儿进程就是失去了原本父亲的进程,1号进程好比是孤儿院,专门处理孤儿进程的善后工作,因此孤儿进程不会对系统产生什么危害。
> >
在 Linux 中,当一个进程的父进程退出或者结束后,而该进程还在运行,这个进程就成为孤儿进程。孤儿进程会被 init 进程(PID 为 1)接管,init 进程会定期地调用
wait()系统调用来回收孤儿进程的资源,防止它们成为僵尸进程。孤儿进程的产生可以有以下几种情况:
- 父进程提前退出:父进程在子进程退出前退出,导致子进程成为孤儿进程。
- 父进程忘记回收子进程:父进程没有在子进程退出时调用
wait()等待子进程退出,导致子进程成为孤儿进程。- 父进程被信号中断:父进程在等待子进程退出时被信号中断,导致子进程成为孤儿进程。
为了避免产生孤儿进程,父进程通常会在创建子进程后调用
wait()或者waitpid()等待子进程退出,并回收子进程的资源。
# 于超老师教你用python实现,孤儿进程。
[root@yuchao-linux01 ~]# cat guer.py
#coding:utf-8
import os
import sys
import time
pid = os.getpid()
ppid = os.getppid()
print 'im father: ', 'pid: ', pid, 'ppid: ', ppid
son_pid = os.fork()
print('now song_pid is: ',son_pid)
#执行pid=os.fork()则会生成一个子进程
#返回值pid有两种值:
# 如果返回的pid值为0,表示在子进程当中
# 如果返回的pid值>0,表示在父进程当中
if son_pid > 0:
print 'father going die...'
# 让老父亲,主动退出,挂掉
sys.exit(0)
# 保证主线程退出完毕
# 程序延迟了1秒,还在运行中,儿子进程还未挂,成了孤儿
time.sleep(2)5
print 'im child: ', os.getpid(),'now my father is: ', os.getppid()
查看孤儿进程
[root@yuchao-linux01 ~]# python guer.py
im father: pid: 1953 ppid: 1930
('now song_pid is: ', 1954)
father going die...
('now song_pid is: ', 0)
[root@yuchao-linux01 ~]# im child: 1954 now my father is: 1
[root@yuchao-linux01 ~]#
1.程序运行时,生成了父亲进程、儿子进程
2.父亲进程突然挂了、儿子成了孤儿,被1号进程收养
3.儿子进程的诞生是为了执行程序,程序结束后,被1号进程释放,消失在了这个美丽的世界。
僵尸进程
1.僵尸听着明显比孤儿进程可怕些,是有害的
2.父亲进程创建出子进程后,如果子进程先挂了,父进程却不知道儿子进程挂了这件事,就无法正确送走儿子进程,清楚它在系统中的信息,那么这个儿子进程就成了可怕的僵尸进程,会对系统产生危害。
3.当系统中有了僵尸进程,你可以通过ps命令找到它,并且它的状态是(Z,zombie僵尸进程)
4.如果系统中产生大量僵尸进程,占据了系统中大量可分配的资源,如进程id号,系统就无法再正确创建新进程,完成任务,导致系统无法使用的危害。
在 Linux 中,当一个进程终止,但其父进程没有及时处理(即没有调用 wait() 或 waitpid() 等待子进程退出),这个已经终止但仍占用系统进程表中一个表项的进程就被称为僵尸进程。僵尸进程不会再消耗 CPU 或内存等资源,但会占用一个进程 ID 直到其父进程处理它。
僵尸进程的存在是正常的,但如果大量积累可能会导致进程表被耗尽。通常情况下,父进程应该及时处理子进程的退出状态,以避免僵尸进程的产生。
要处理僵尸进程,父进程可以通过以下方式之一:
- 在信号处理函数中调用
wait()或waitpid()来等待子进程退出,这样当子进程退出时,父进程会收到SIGCHLD信号,可以在信号处理函数中处理子进程的退出状态。 - 定期检查子进程的退出状态,以确保没有僵尸进程存在。可以使用循环调用
waitpid(),并检查返回值是否为 0,来处理所有已经退出的子进程。 - 使用
sigaction()函数设置SIGCHLD信号的处理函数,这样在子进程退出时会自动调用处理函数来处理子进程的退出状态。
通过及时处理子进程的退出状态,可以避免僵尸进程的产生,并确保系统资源的正常释放。
# 于超老师教你用python实现,僵尸进程
#coding:utf-8
from multiprocessing import Process
import time,os
def run():
print('son_pid: ',os.getpid())
if __name__ == '__main__':
p=Process(target=run)
p.start()
print('father_pid: ',os.getpid())
time.sleep(1000)
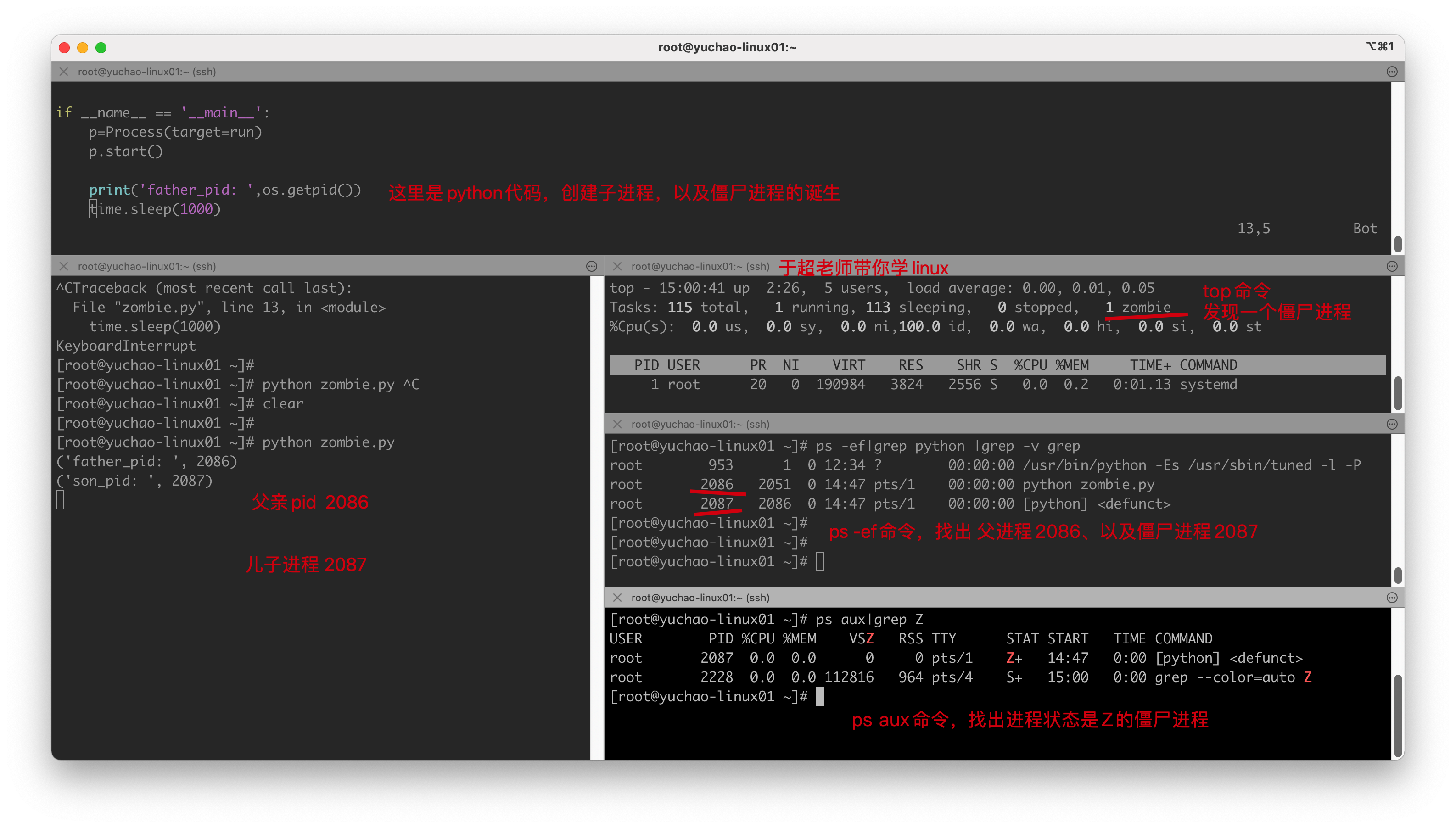
验证僵尸进程的确存在
[root@yuchao-linux01 ~]# ps -ef|grep 2086 |grep -v grep
root 2086 2051 0 14:47 pts/1 00:00:00 python zombie.py
root 2087 2086 0 14:47 pts/1 00:00:00 [python] <defunct>
[root@yuchao-linux01 ~]# ps aux|grep Z |grep -v grep
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 2087 0.0 0.0 0 0 pts/1 Z+ 14:47 0:00 [python] <defunct>
怎么解决僵尸进程
杀死父进程
优化代码,不要再写这种垃圾代码了,把unix高级编程,好好学学。
- 开除、换一个更懂操作系统的程序员。
使用信号处理程序:在父进程中设置 SIGCHLD 信号的处理程序,当子进程退出时,会发送 SIGCHLD 信号给父进程。在信号处理程序中调用 wait() 或 waitpid() 来等待子进程退出并回收其资源。
定期检查子进程状态:在父进程中定期调用 waitpid() 来检查是否有子进程退出,并及时回收资源。
避免父进程提前退出:确保父进程在子进程退出前不会提前退出。
通过这些方法,可以及时处理子进程的退出状态,避免僵尸进程的产生。
轻松理解僵尸进程
全中国的中国移动网络好比是一个操作系统,控制着全中国的移动用户通信,每一个中国百姓就是一个进程,每一个百姓都有一个手机号,该号码就好比进程的pid,对应这个进程。
2.如果这个人再也不用手机了,不要手机号了,应该去移动注销手机号(告诉操作系统,回收pid)
3.如果不去注销(不回收pid),这个手机号依然被你保留着,毫无意义不说,且占用了一个号码,浪费手机号,(浪费系统中pid的资源),应该去释放手机号。
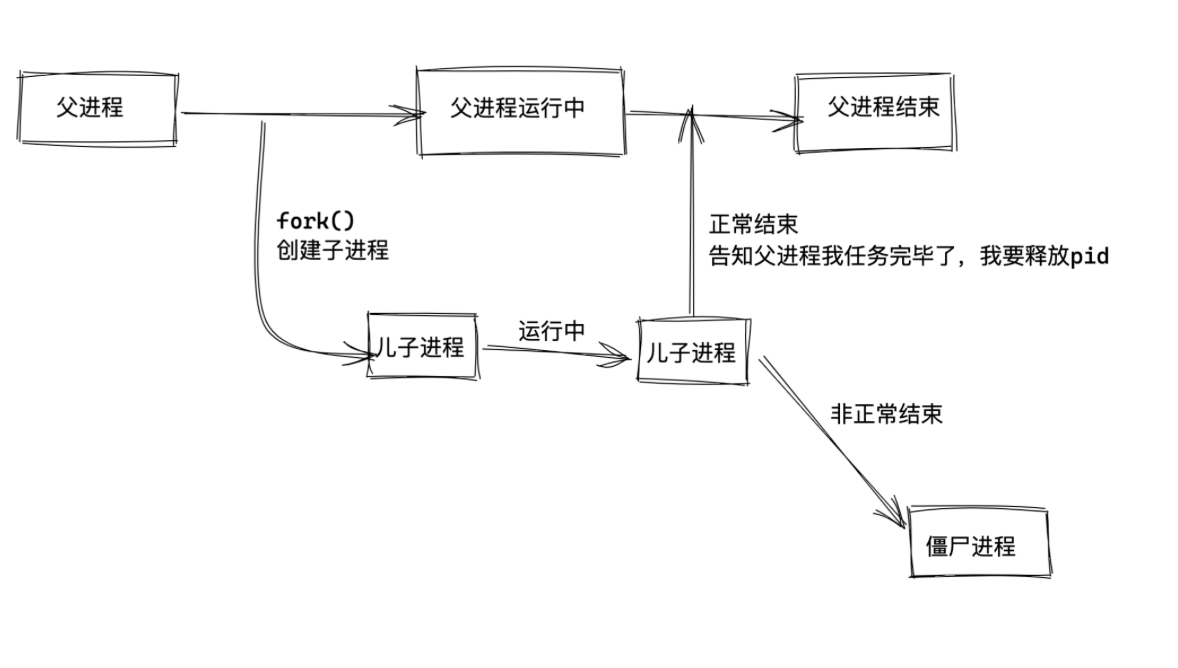
进程的生命周期
在 Linux 中,进程的生命周期通常包括以下几个阶段:
- 创建(Creation):进程通过调用
fork()系统调用(或其他创建进程的方式)由父进程创建。新进程获得父进程的地址空间的副本,但是有自己独立的内存空间和进程标识符(PID)。 - 就绪(Ready):新创建的进程处于就绪状态,等待被调度执行。在多道程序系统中,操作系统会根据调度算法从就绪队列中选择一个进程执行。
- 运行(Running):被调度执行的进程处于运行状态,正在使用 CPU 执行指令。一个进程在任意时刻只能在一个 CPU 核心上运行。
- 阻塞(Blocked):进程在某些情况下(如等待 I/O 操作完成、等待信号等)会进入阻塞状态,此时进程暂停执行,不会占用 CPU 时间。
- 终止(Termination):进程在完成其任务后或接收到终止信号时会进入终止状态。在终止状态下,进程的资源会被释放,但是其父进程需要调用
wait()或waitpid()来回收子进程的资源,否则进程会成为僵尸进程。 - 僵尸(Zombie):如果一个进程终止,但其父进程没有及时处理(调用
wait()或waitpid()),那么该进程会成为僵尸进程,直到其父进程回收其资源或者父进程退出。 - 结束(Exit):当进程的资源被回收后,进程就完全结束了其生命周期。
这是进程在 Linux 中的一般生命周期,不同的操作系统和环境可能会有一些差异。理解进程的生命周期有助于编写更好的程序,避免僵尸进程等问题。
进程管理命令
如果你发现电脑奇卡无比,你可能就得打开任务管理器,找找是哪个程序,占用CPU,内存,磁盘资源特别高,如果它没有用,干掉即可。
同样的,运维维护linux服务器,要保证机器健康运行,第一步就是盯紧了服务器的CPU,内存,磁盘,网络,这几大资源使用率。
在Linux中,有许多命令用于管理进程。以下是一些常用的进程管理命令:
ps:显示当前运行的进程的快照。ps aux:显示所有用户的所有进程。ps -ef:显示系统中所有进程的详细信息。
top:实时显示系统中各个进程的资源占用情况。htop:类似于top,但提供了更多的交互式功能和可视化效果。kill:终止指定进程。kill -9 PID:强制终止指定PID的进程。
killall:终止指定名称的所有进程。killall process_name:终止所有名为process_name的进程。
pgrep:根据进程名查找进程的PID。pgrep process_name:查找名为process_name的进程的PID。
pkill:根据进程名终止进程。pkill process_name:终止名为process_name的进程。
pidof:查找指定进程名的PID。pidof process_name:查找名为process_name的进程的PID。
pstree:以树状图显示进程的层次结构。renice:修改进程的优先级。renice priority PID:将PID指定的进程的优先级修改为priority。
这些是一些常用的Linux进程管理命令,可以帮助您监视、查找和控制系统中运行的进程。
top
top 命令用于动态显示系统中运行的进程的信息,包括进程的PID、用户、CPU占用率、内存占用率等。它可以帮助您快速了解系统的运行情况,并查找可能占用资源过多的进程。
要使用 top 命令,只需在终端中输入 top 并按回车键即可。默认情况下,top 每隔一段时间刷新一次显示的进程信息。您可以使用以下键盘快捷键来与 top 命令进行交互:
h:显示帮助信息,包括可用的键盘快捷键。k:向进程发送信号以终止进程。输入此命令后,将提示输入要终止的进程的PID,然后按回车键。q:退出top命令。Space:立即刷新显示的进程信息。1:切换到显示每个CPU核心的详细信息。c:cpu排序m:更换内存显示格式,大写M内存排序u:显示指定用户的进程。输入此命令后,将提示输入要显示的用户名,并按回车键。
您还可以使用命令行选项来控制 top 命令的行为。例如,top -n 5 将仅显示前五次刷新的信息,然后退出。详细的选项信息可以通过 man top 命令查看 top 命令的手册页。
ps命令用法
ps 命令用于显示当前运行的进程快照。它提供了许多选项,可以用来过滤和格式化输出。以下是一些常用的 ps 命令用法:
显示当前用户的所有进程:
ps显示所有用户的所有进程:
ps aux显示所有进程的完整信息:
ps -ef显示指定用户的进程:
ps -u username仅显示进程的PID和命令名:
ps -eo pid,cmd显示指定进程的详细信息:
ps -p PID -o pid,ppid,user,cmd,%cpu,%mem按照CPU使用率排序并显示前几个进程:
ps aux --sort=-%cpu | head查找特定进程的PID:
ps -ef | grep process_name显示进程树结构:
ps -e --forest
这些是 ps 命令的一些常见用法。您可以使用 man ps 命令查看 ps 命令的完整用法和选项。
ps结果
root@VM-8-7-ubuntu:~# ps -ef|head
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Mar16 ? 00:00:11 /sbin/init
root 2 0 0 Mar16 ? 00:00:00 [kthreadd]
root 3 2 0 Mar16 ? 00:00:00 [rcu_gp]
root 4 2 0 Mar16 ? 00:00:00 [rcu_par_gp]
root 5 2 0 Mar16 ? 00:00:00 [slub_flushwq]
root 6 2 0 Mar16 ? 00:00:00 [netns]
root 8 2 0 Mar16 ? 00:00:00 [kworker/0:0H-events_highpri]
root 10 2 0 Mar16 ? 00:00:00 [mm_percpu_wq]
root 11 2 0 Mar16 ? 00:00:00 [rcu_tasks_rude_]
root@VM-8-7-ubuntu:~#
当您运行 ps 命令时,它会显示当前系统中运行的进程的快照。输出的每一行代表一个进程,列出了进程的各种信息。以下是 ps 命令输出中常见的一些列以及它们的含义:
- PID:进程的ID,唯一标识一个进程。
- TTY:进程关联的终端(如果有的话)。
- TIME:进程使用的CPU时间。
- CMD:进程的命令名称。
ps 命令的输出可能因操作系统和命令选项而异。您可以根据需要使用不同的选项来定制输出格式和内容。例如,ps aux 命令显示所有用户的所有进程,而 ps -ef 命令显示所有进程的完整信息。
如果您需要更详细的信息,可以使用 ps 命令的其他选项,如 -o(指定要显示的列)和 -p(指定要显示的进程ID)。您还可以结合使用 grep 等命令来过滤输出,以便更容易地查找特定的进程。
进程状态
USER:显示该进程所属的用户。
PID:显示该进程的进程号。
%CPU:显示该进程占用CPU资源的百分比。
%MEM:显示该进程占用物理内存的百分比。
VSZ:显示该进程使用的虚拟内存大小(单位为Kbytes)。
RSS:显示该进程占用的固定内存大小(单位为Kbytes)。
TTY:显示该进程所在的终端。
STAT
:显示该进程的状态,例如:
- R:运行中。
- S:休眠状态,可被唤醒。
- D:不可中断的休眠状态。
- T:停止状态。
- Z:僵尸状态,进程已终止但父进程尚未收到终止信号。
START:显示该进程启动的时间。
TIME:显示该进程在CPU上的运行时间。
COMMAND:显示该进程的命令名称。
补充说明:
- 如果命令名称被方括号(
[])括起来,表示该进程是内核线程。 - 前台进程(Foreground Process)通常指正在前台运行的进程,它们可以接收用户输入,后台进程(Background Process)通常指在后台默默运行的进程。
pstree
pstree 命令用于以树状图形式显示进程之间的关系。它将当前系统中运行的进程按照父子关系进行展示,使得进程之间的层次结构一目了然。
pstree 命令通常用法简单,只需在终端中输入 pstree 即可。默认情况下,pstree 将显示当前用户及其子进程的进程树。您还可以结合一些选项来定制输出,例如:
-p:显示进程ID。-u:显示进程的所有者。-a:显示命令行参数。-h:高亮显示当前进程。
例如,要显示所有进程的树状图以及进程ID和命令行参数,可以使用以下命令:
pstree -ap
pstree 命令提供了一种直观地查看系统中进程关系的方式,特别适用于了解复杂进程之间的层次结构和依赖关系。
其他进程管理命令
在Linux中,管理进程的常用命令包括:
ps:显示当前运行的进程快照。ps aux:显示所有用户的所有进程。ps -ef:显示系统中所有进程的详细信息。
top:动态显示系统中各个进程的资源占用情况。htop:类似于top,但提供了更多的交互式功能和可视化效果。glances由python开发的一款跨平台,资源管理器,支持python二次定制,支持远程http看数据。apt install glances -ykill:终止指定进程。kill PID:终止指定PID的进程。killall process_name:终止所有名为process_name的进程。
pkill:根据进程名终止进程。pkill process_name:终止名为process_name的进程。
pgrep:根据进程名查找进程的PID。pgrep process_name:查找名为process_name的进程的PID。
renice:修改进程的优先级。renice priority PID:将PID指定的进程的优先级修改为priority。
pstree:以树状图显示进程的层次结构。
这些命令提供了管理和监视Linux系统中运行进程的基本功能。可以根据具体需求选择合适的命令进行操作。
lsof
lsof(List Open Files)命令用于显示系统中已打开文件的信息,包括普通文件、目录、网络连接、设备文件等。
它可以帮助您查看哪些进程正在使用哪些文件或网络连接,对于系统排查和监控非常有用。
以下是一些常见的 lsof 命令用法:
显示所有打开的文件:
lsof显示指定进程打开的文件:
lsof -p PID显示指定用户打开的文件:
lsof -u username显示指定目录下被打开的文件:
lsof +D /path/to/directory显示指定文件被哪些进程打开:
lsof /path/to/file显示网络连接信息:
lsof -i显示指定端口被哪些进程使用:
lsof -i :port_number
lsof 命令的输出包含很多列,其中常见的列及其含义包括:
- COMMAND:打开文件的进程名。
- PID:进程ID。
- USER:进程的所有者。
- FD:文件描述符,表示文件如何被打开(如cwd、txt、mem等)。
- TYPE:文件类型,如REG(普通文件)、DIR(目录)、IPv4(IPv4套接字)等。
- DEVICE:文件所在设备的名称。
- SIZE/OFF:文件的大小或偏移量。
- NODE:文件的节点号。
- NAME:文件名或网络连接信息。
lsof 命令非常强大,可以帮助您了解系统中文件和网络连接的使用情况,但输出信息可能会很庞大,需要根据具体情况进行过滤和分析。
kill
kill 命令用于终止指定进程。它向指定进程发送信号,告诉进程要终止。默认情况下,kill 命令会发送 TERM 信号(信号编号为 15),这会请求进程正常退出。如果进程未响应 TERM 信号,您可以使用 -9 选项发送 KILL 信号(信号编号为 9),这会强制终止进程。
以下是 kill 命令的基本用法:
kill PID
其中,PID 是要终止的进程的进程ID。您可以使用 ps 命令查找进程的PID,然后将其传递给 kill 命令。
kill 命令还支持以下常用选项:
-9:发送 KILL 信号,强制终止进程。-15(或-TERM):发送 TERM 信号,请求进程正常退出。-l:列出所有可用的信号名称。
例如,要终止进程ID为 1234 的进程,您可以使用以下命令:
kill 1234
如果进程不响应 TERM 信号,您可以尝试发送 KILL 信号:
kill -9 1234
请注意,强制终止进程可能会导致数据丢失或其他意外情况,因此建议先尝试使用 TERM 信号正常终止进程。
什么是信号(signal)
简单说就是向进程发送的一个控制信号,一般用于杀死、停止进程。
每个信号都用一个数字表示。
在Linux和类Unix操作系统中,信号(signal)是一种用于通知进程发生某种事件的机制。信号可以由内核、其他进程或操作系统发送给目标进程。进程可以根据接收到的信号做出相应的动作,例如终止进程、暂停进程、重新加载配置等。
每个信号都有一个唯一的编号,用来标识不同的事件。一些常见的信号包括:
SIGINT(编号为2):由键盘生成的中断信号,通常是用户按下Ctrl+C终止前台进程。SIGTERM(编号为15):终止信号,通常用来请求进程正常退出。SIGKILL(编号为9):强制终止信号,用于立即终止进程。SIGSTOP(编号为19):停止信号,用于暂停进程的执行。SIGCONT(编号为18):继续信号,用于恢复被暂停的进程。
进程可以使用 signal 函数或 sigaction 函数来注册信号处理函数,以定义在接收到特定信号时应该执行的操作。信号处理函数可以是预定义的处理方式,也可以是用户自定义的处理函数。
总的来说,信号是进程之间或进程与内核之间进行通信的一种简单有效的方式,可以用于处理各种事件和情况。
kill信号组合
kill 命令可以与不同的信号组合使用,以实现不同的操作。下面是一些常用的 kill 命令与信号组合:
终止进程:使用
SIGTERM(信号编号为 15)信号请求进程正常退出。kill PID或者
kill -15 PID这会向进程发送终止信号,让进程有机会进行清理工作并正常退出。
强制终止进程:如果进程不响应
SIGTERM,可以使用SIGKILL(信号编号为 9)信号强制终止进程。kill -9 PID这会立即终止进程,不会给进程进行清理工作的机会,可能会导致数据丢失。
暂停和继续进程:可以使用
SIGSTOP(信号编号为 19)信号暂停进程的执行,然后使用SIGCONT(信号编号为 18)信号继续进程的执行。kill -STOP PID # 暂停进程kill -CONT PID # 继续进程重新加载配置:有些进程在接收到
SIGHUP(信号编号为 1)信号时会重新加载配置文件。kill -HUP PID安全重启:某些服务进程在接收到
SIGUSR1或SIGUSR2信号时会执行安全重启。kill -USR1 PID # 安全重启
这些是 kill 命令常用的信号组合,可以根据需要选择适当的信号来控制进程的行为。
后台运行进程
在Linux中,可以使用几种方法将进程在后台运行,使其不会阻塞当前终端。下面是几种常用的方法:
使用
&符号:在命令的末尾添加&符号可以使命令在后台运行。例如:command &使用
nohup命令:nohup命令可以让命令在后台运行,并且不受当前会话的影响,即使关闭终端也不会停止进程。例如:```
公司启动项目,确保你下班了,电脑关了,程序也后台不断运行
nohup command &
ping 命令举例
正确写法,后台运行,且重定向
nohup ping yuchaoit.cn > /tmp/yuchaoit.log &
3. **使用`screen`命令**:`screen`命令可以创建一个虚拟终端,允许在其中运行命令,并且可以在不同的终端之间切换。例如:
screen -S session_name
进入虚拟终端后,运行命令,然后按下`Ctrl+A`,然后按下`D`来将其放入后台运行。可以使用`screen -r session_name`来重新连接到虚拟终端。
4. **使用`disown`命令**:`disown`命令可以将之前使用`&`符号后台运行的命令从当前终端中分离,使其不受终端关闭的影响。例如:
command & disown
这些方法可以让命令在后台运行,并且不受当前终端会话的影响。选择合适的方法取决于您的需求和偏好。
# 详解linux数据流
在Linux中,数据流(data stream)是指数据在系统内部或与外部设备之间传输的方式。数据流可以是从一个进程到另一个进程、从一个进程到文件、从文件到一个进程,或者在网络上传输的数据。在Linux中,数据流可以分为三种类型:标准输入(stdin)、标准输出(stdout)和标准错误输出(stderr)。
1. **标准输入(stdin)**:通常表示为文件描述符 0,用于接收输入数据。当一个程序从标准输入读取数据时,它实际上是从键盘或另一个进程(通过管道)读取数据。例如,使用 `<` 符号可以将文件内容重定向到标准输入:
cat < file.txt
2. **标准输出(stdout)**:通常表示为文件描述符 1,用于输出数据。当一个程序将数据写入标准输出时,它实际上是向终端或另一个进程(通过管道)输出数据。例如,使用 `>` 符号可以将命令的输出重定向到文件:
ls > output.txt
ls /tmp 1> 1.txt
3. **标准错误输出(stderr)**:通常表示为文件描述符 2,用于输出错误消息。与标准输出类似,标准错误输出可以重定向到文件或另一个进程。通常情况下,标准错误输出会显示在终端上,用于提示用户发生了错误。例如,使用 `2>` 符号可以将错误消息重定向到文件:
command_not_exist 2> error.log
lsssssssssss /opt 2> 1.txt root@VM-8-7-ubuntu:~# cat 1.txt lsssssssssss: command not found
除了标准输入、输出和错误输出之外,Linux还支持管道(`|`)和重定向符号来操作数据流。管道可以将一个命令的输出作为另一个命令的输入,而重定向符号可以将命令的输入、输出或错误输出重定向到文件或其他命令。这些功能使得在Linux系统中对数据流进行灵活的控制成为可能。
## 2>&1
`2>&1` 是一种重定向操作符,用于将标准错误输出(stderr,文件描述符 2)重定向到标准输出(stdout,文件描述符 1)。这意味着错误消息将与普通输出一样处理,可以一起输出到终端或重定向到文件中。
例如,假设有一个命令 `command`,我们希望将其输出和错误消息都重定向到同一个文件 `output.txt` 中,可以这样使用:
默认linux 命令输出,stdout和stderr是分开的
结合输出到一起,你可以吧2的数据流,也写入1,这样,就可以合并,正确,错误的输出了。
command > output.txt 2>&1
这条命令先将标准输出重定向到 `output.txt` 文件,然后使用 `2>&1` 将标准错误输出重定向到与标准输出相同的地方,也就是 `output.txt` 文件中。

## stderr和stdout
在 Linux 和类 Unix 系统中,标准输出(stdout)和标准错误输出(stderr)是两个常见的输出流,用于将信息发送到终端或其他设备。这两个输出流在进程通信和错误处理中起着重要作用。
1. **标准输出(stdout)**:
- 文件描述符:通常表示为 1。
- 作用:用于向用户显示正常输出信息,如程序的结果、普通信息和警告等。
- 示例:`echo "Hello, world!"` 将字符串 "Hello, world!" 输出到标准输出。
2. **标准错误输出(stderr)**:
- 文件描述符:通常表示为 2。
- 作用:用于向用户显示错误消息、警告和其他非正常输出信息。
- 示例:`cat nonexistent_file.txt` 尝试读取一个不存在的文件,将会在标准错误输出中显示错误消息。
在终端中,默认情况下,stdout 和 stderr 都会显示在屏幕上,但是您可以使用重定向来将它们发送到文件或管道中,以便后续处理或记录。
示例:
- 将 stdout 重定向到文件:`ls > file_list.txt` 将当前目录下的文件列表写入 `file_list.txt` 文件。
- 将 stderr 重定向到文件:`ls nonexistent_dir 2> error.log` 将错误消息写入 `error.log` 文件,而不会显示在屏幕上。
- 合并 stdout 和 stderr 并重定向到同一文件:`command > output.txt 2>&1` 将 stdout 和 stderr 都重定向到 `output.txt` 文件中。
正确处理和区分 stdout 和 stderr 对于排查和调试问题非常重要。通过了解这两个输出流的工作方式,您可以更好地控制和处理程序的输出。

# 机器负载
## 理解
Linux 机器的负载是指系统中正在使用和等待使用 CPU 和其他资源的程度。
它通常用平均负载值(load average)来表示,在 Linux 中可以通过 `uptime`、`top` 等命令查看。
平均负载值是指在过去 1 分钟、5 分钟和 15 分钟内运行队列中的平均进程数。
例如,一个平均负载值为 1.0 的系统表示平均有一个进程在运行队列中等待执行。
理想情况下,负载应该保持在系统 CPU 核心数的合理范围内(通常为 1.0 或略高),以确保系统能够及时响应请求。
如果负载过高,系统可能会变得缓慢或无响应,需要进一步分析和处理,可能包括优化应用程序、增加硬件资源等措施。
## 命令
要查看 Linux 机器的负载,可以使用以下几种方法:
1. **使用 `uptime` 命令**:
uptime
`uptime` 命令会显示系统的运行时间以及当前的负载情况。负载信息包括系统在过去 1 分钟、5 分钟和 15 分钟内的平均负载。
2. **使用 `top` 命令**:
top
`top` 命令会动态显示系统中运行的进程信息,包括负载情况、CPU 使用率、内存使用率等。在 `top` 命令的输出中,负载信息通常显示在顶部行的第二个字段。
3. **使用 `w` 命令**:
w
`w` 命令显示当前登录用户的信息,包括系统负载。系统负载信息通常显示在第一行的最后面。
4. **查看 `/proc/loadavg` 文件**:
cat /proc/loadavg
`/proc/loadavg` 文件包含了系统的负载信息,以及在过去 1 分钟、5 分钟和 15 分钟内的平均负载。
这些方法可以帮助您了解 Linux 系统的负载情况,以便及时采取措施处理高负载问题。
## 负载测试
在 Linux 中进行负载测试通常涉及模拟大量请求或任务,以测试系统在高负载下的表现。这种测试可以帮助您评估系统的性能、稳定性和容量。
以下是一些常用的 Linux 负载测试工具和方法:
1. **stress 工具**:`stress` 是一个用于模拟 CPU、内存、I/O 等资源压力的工具。您可以使用 `stress` 命令来创建指定数量的进程,以测试系统在不同负载下的表现。
- 安装 stress工具(在 Ubuntu 上):
sudo apt update
sudo apt install stress
```
使用 stress 命令模拟 CPU 负载:
stress --cpu 1 --timeout 10s使用 stress命令模拟内存负载:
stress --vm 2 --vm-bytes 1024M --timeout 60s
Apache Benchmark (ab):
ab工具可以用来测试 Web 服务器的性能,在高负载下测试服务器的响应能力。安装 Apache Benchmark(在 Ubuntu 上):
sudo apt update sudo apt install apache2-utils -y使用 ab命令测试网站的性能:
ab -n 100000 -c 100 http://49.232.220.205/yuchao.html这将向
http://example.com/发送 1000 个请求,并发数为 100。
自定义脚本:您还可以编写自定义脚本来模拟特定负载情况。例如,使用 Bash 脚本循环执行任务,或者使用 Python 脚本模拟网络请求。
在进行负载测试时,请注意避免对生产环境产生负面影响。最好在测试环境中进行测试,并确保备份数据以防意外发生。
内存运维
Linux 运维中,内存管理是一个重要的方面,因为它直接影响系统的性能和稳定性。以下是一些常见的 Linux 内存管理任务和工具:
查看内存使用情况:
free命令:显示系统的内存使用情况,包括总内存、已用内存、空闲内存等。
free -htop命令:显示系统中进程的实时信息,包括内存使用情况。
tophtop命令:类似于 top,但提供了更多的交互式功能和可视化效果。
htop
查看内存详细信息:
/proc/meminfo 文件:包含有关内存使用情况的详细信息,如内存总量、空闲内存、缓冲区和缓存的使用情况等。
cat /proc/meminfo
查看进程的内存使用情况:
ps命令:显示系统中运行的进程信息,包括内存使用情况。
ps aux
清理内存:
使用 sync命令刷新文件系统缓存,释放未使用的缓存内存。
sync使用
echo 1 > /proc/sys/vm/drop_caches命令清理页缓存。使用
echo 2 > /proc/sys/vm/drop_caches命令清理目录项和inode。使用
echo 3 > /proc/sys/vm/drop_caches命令清理页缓存、目录项和inode。echo 1 > /proc/sys/vm/drop_caches echo 2 > /proc/sys/vm/drop_caches echo 3 > /proc/sys/vm/drop_caches
内存交换(swap)管理:
swapon和 swapoff命令用于启用或禁用交换分区。
``` swapon /dev/sdX # 启用交换分区 swapoff /dev/sdX # 禁用交换分区
内存不足,系统从磁盘上分配一些空间,给程序当内存用,性能很差!高并发环境下肯定是关闭。 当下内存资源都不算贵,企业都会花钱换来性能。
磁盘 容量大,速度慢 内存,容量小,速度极快
```
以上是一些常见的 Linux 内存管理任务和工具,您可以根据需要使用这些工具来监控和管理系统的内存使用情况。
free命令
free 命令用于显示系统内存的使用情况,包括物理内存和交换空间(swap)的信息。以下是 free 命令的常用选项及其含义:
-h, --human:以人类可读的格式显示输出。-b, --bytes:以字节为单位显示内存使用情况。-k, --kilo:以千字节为单位显示内存使用情况。-m, --mega:以兆字节为单位显示内存使用情况。-g, --giga:以吉字节为单位显示内存使用情况。-t, --total:显示总计行,包括总内存、已使用、空闲、共享、缓冲区和可用内存的信息。
使用 free 命令时,可以使用 -h 选项以人类可读的格式显示内存使用情况,如下所示:
free -h
输出示例:
vbnetCopy code
total used free shared buff/cache available
Mem: 7.7Gi 1.3Gi 3.7Gi 218Mi 2.6Gi 5.9Gi
Swap: 7.9Gi 0B 7.9Gi
输出中的字段解释如下:
- total:物理内存总量。
- used:已使用的物理内存量。
- free:空闲的物理内存量。
- shared:被共享的内存量。
- buff/cache:用作缓冲区和缓存的内存量。
- available:可用内存量。
在输出中,除了物理内存信息外,还包括了交换空间(swap)的信息,显示了交换空间总量、已使用和空闲的交换空间量。
free 命令是一个简单而强大的工具,用于快速查看系统的内存使用情况,帮助您及时了解系统的性能和资源状况。
buff和cache
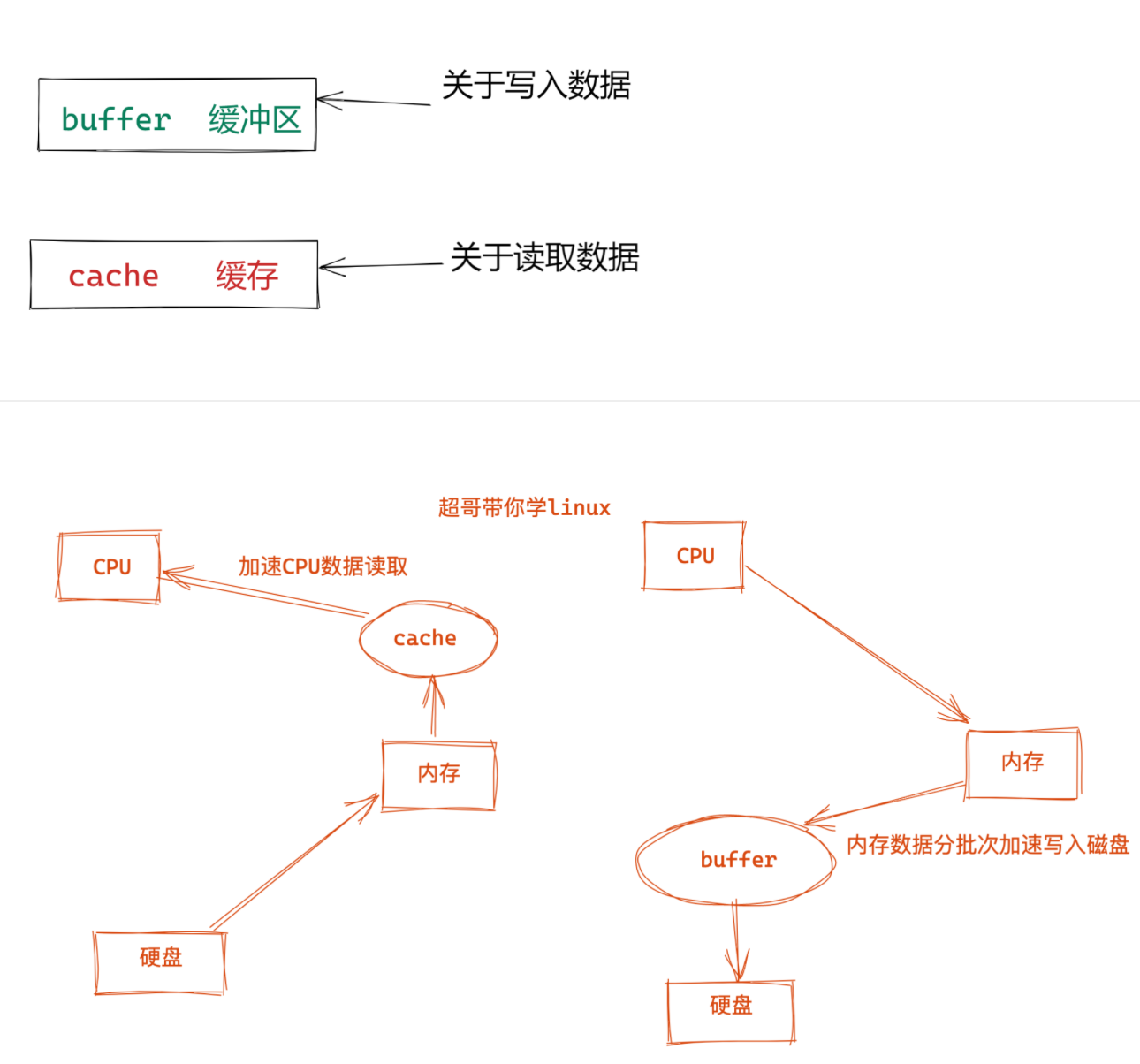
buff/cache 是 free 命令输出中的一个字段,表示用作缓冲区和缓存的内存量。在 Linux 系统中,内核会使用一部分内存作为缓冲区和缓存,以提高文件系统性能和响应速度。这些缓冲区和缓存用于存储文件系统的元数据和数据块,以减少对硬盘的访问次数,从而加快文件读写操作。
- 缓冲区(Buffer):缓冲区用于存储文件系统的元数据(如目录、文件属性等)和数据块(文件内容)。当系统读取文件时,会先将数据读入缓冲区,如果下次需要相同的数据,就可以直接从缓冲区读取,避免再次访问磁盘。
- 缓存(Cache):缓存用于存储最近访问过的文件数据块,以便在将来访问时快速读取。缓存中的数据可以被多个进程共享,因此对于经常访问的文件,可以减少磁盘 I/O 操作,提高系统性能。
在 free 命令的输出中,buff/cache 字段显示的是用于缓冲区和缓存的内存总量,包括已使用和空闲的部分。这部分内存实际上是空闲的,但被内核用作缓冲区和缓存,可以随时被释放给应用程序使用。
通常情况下,缓冲区和缓存的内存占用量会随着系统的运行时间和文件系统的使用而增加,这是正常的现象。系统会根据需要动态调整缓冲区和缓存的大小,以提高系统性能并合理利用内存资源。
磁盘io运维
io是什么
I/O(Input/Output)指的是计算机系统与外部设备之间的数据交换过程。
在计算机系统中,I/O 操作是指从外部设备读取数据到计算机内存或将计算机内存中的数据写入外部设备的过程。
I/O 操作涉及到磁盘、网络、键盘、显示器等设备。
在操作系统中,I/O 通常分为两种类型:阻塞式 I/O 和非阻塞式 I/O。
- 阻塞式 I/O:当应用程序发起 I/O 请求时,如果设备无法立即完成操作(例如磁盘读取数据时磁头需要移动到正确位置),应用程序将被阻塞,直到操作完成为止。
- 非阻塞式 I/O:应用程序发起非阻塞 I/O 请求后,可以继续执行其他任务,而不必等待操作完成。应用程序需要定期检查操作是否完成,并处理相应的状态。
在现代计算机系统中,为了提高 I/O 性能和效率,通常会采用以下技术和方法:
- 缓存:通过在内存中缓存数据,可以减少对磁盘等慢速设备的访问次数,提高读写速度。
- 异步 I/O:允许应用程序在发起 I/O 请求后继续执行其他任务,而无需等待操作完成。
- 多路复用:通过一种机制,使一个进程能够同时监视多个文件描述符,当其中任何一个文件描述符就绪时,都可以对其进行操作,提高了 I/O 的效率。
- DMA(Direct Memory Access):允许外部设备直接访问计算机内存,而不需要经过 CPU 的介入,加快数据传输速度。
I/O 操作是计算机系统中的重要部分,对系统的性能和响应速度有着重要影响。优化 I/O 操作可以显著提高系统的性能和效率。
命令
磁盘 I/O 运维是管理和优化磁盘输入/输出操作的过程,旨在提高系统的性能、可靠性和效率。以下是一些常见的磁盘 I/O 运维任务和技术:
监控磁盘 I/O:
使用 iostat命令监控磁盘 I/O 情况,包括读写速率、I/O 请求等待时间等。
``` 安装apt install sysstat
iostat -d -x 1
- 使用 iotop命令监控磁盘 I/O 活动,并显示哪些进程正在占用磁盘。iotop ```
优化文件系统:
- 使用合适的文件系统(如 ext4、XFS 等),根据需求选择适合的文件系统类型。
- 使用文件系统特性,如 ext4 的日志功能(journaling)来保护文件系统的一致性。
调整调度器:
- 在 Linux 中,可以通过更改磁盘 I/O 调度器来优化磁盘性能。常见的调度器有 deadline、cfq、noop 等。
使用 RAID:
- 使用 RAID(Redundant Array of Independent Disks)技术来提高磁盘性能和可靠性。RAID 可以将多个磁盘组合成一个逻辑单元,并提供数据冗余和/或性能增强。
优化应用程序:
- 优化应用程序的读写操作,减少磁盘 I/O 的频率和量。
- 使用缓存技术(如 Memcached、Redis 等)减少对磁盘的直接访问。
定期清理磁盘空间:
- 定期清理不再需要的文件和日志,以释放磁盘空间并避免磁盘碎片化。
监控磁盘健康状态:
- 使用工具如
smartctl来监控磁盘的健康状态,并及时替换出现故障的磁盘。
- 使用工具如
定期备份数据:
- 定期备份数据以防止数据丢失,并确保备份数据存储在安全的位置。
通过有效的磁盘 I/O 运维,可以提高系统的性能、可靠性和效率,同时延长硬件的使用寿命。
运维怎么学网络
在运维中,理解网络是指理解和管理计算机网络的概念、原理、组件和技术,以确保网络的稳定性、安全性和性能。网络在运维中起着至关重要的作用,因为它连接了各种计算机和设备,使它们能够相互通信和共享资源。
以下是在运维中理解网络的一些关键方面:
- 网络拓扑:理解不同类型的网络拓扑(如星型、总线型、环形、树状和网状拓扑)以及它们的优缺点。
- 网络设备:了解各种网络设备的功能和作用,如交换机、路由器、防火墙、网关等,并知道如何配置和管理这些设备。
- IP 地址和子网:理解 IP 地址的作用和分类,以及如何划分子网和管理子网。
- 网络协议:熟悉常见的网络协议,如TCP/IP 协议栈、HTTP、FTP、SMTP、DNS 等,并知道它们的作用和工作原理。
- 网络安全:了解网络安全的基本概念和原则,包括防火墙、入侵检测系统(IDS)、虚拟专用网络(VPN)等技术。
- 网络性能优化:了解如何优化网络性能,包括带宽管理、流量控制、负载均衡等技术。
- 故障排除:掌握常见的网络故障排除技巧,能够快速定位和解决网络问题。
- 监控和管理工具:熟悉各种网络监控和管理工具,如Wireshark、Nagios、Zabbix、Cacti 等,能够使用这些工具监控和管理网络。
- 云计算和容器化:了解云计算和容器化技术对网络架构和运维的影响,以及如何在这些环境下管理网络。
理解和掌握这些网络概念和技术,对于网络运维人员来说是至关重要的,可以帮助他们更好地管理和维护复杂的计算机网络环境。
网络
网络知识,涉及较多的原理性概念,放在后面再讲,先学实践性的linux操作。
计算机网络,就是一堆协议组成起来的。
- 于超老师给大家发送linux学习资料,是直接通过电脑,把文件等资料发到你们的机器上,至于怎么发的,我们就知道是得确保我们互相的机器都能上网,资料就发过去了。
- 如果没有网络,我们两人的计算机,需要插上网线,将两个机器连接起来,才能进行数据传输,但是现在有了更方便的网络,蓝牙等无线信号,能够隔空传输数据了。
- 不限于机器时间的文件传输,还有其他各种需求,域名解析、www网络服务,ping命令的icmp协议,VPN的特殊协议,时间同步的ntp协议、等等,这些协议是专业网络工程师要去学习的。
而我们作为系统工程师,更多的是关注linux操作系统本身,对于网络有一定的认识,能够进行运维工作实践即可,当然后期,晋升高级运维,学习的内容越来越复杂,必然要对网络有更多的认识。
全世界找不出任何一个人能搞懂网络传输的过程,因为其中涉及了太复杂的数据交换,你只需要记住。
- 好比你发快递,记住发送人是谁,收件人是谁,具体这个快递是经过了山路十八弯,还是去南极跑了一圈,你不用管,你关心最后快递能送到即可。
- 你只需要关心,你和对方的服务器,是否能通信即可。
网络协议之TCP、UDP
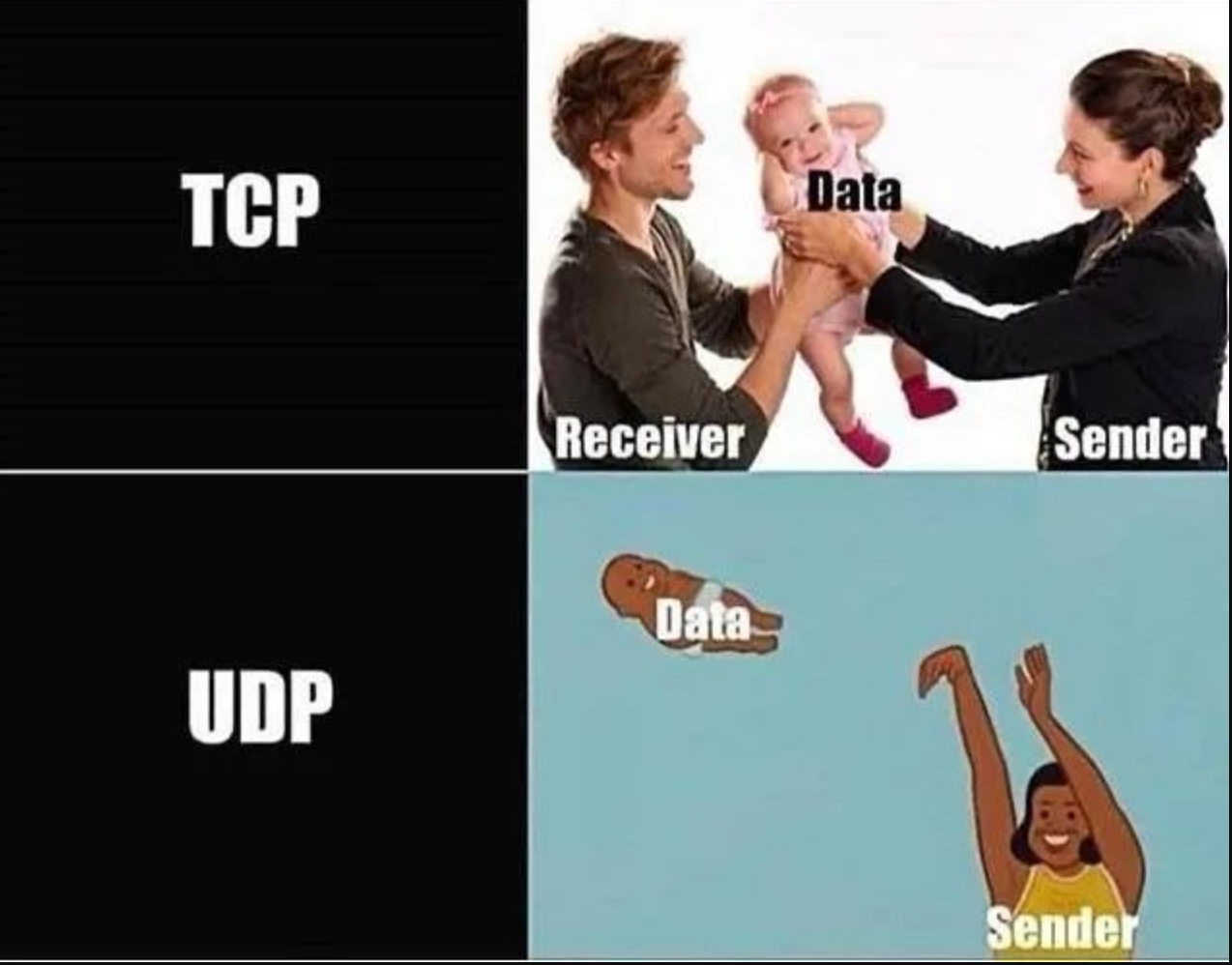
我们学习netstat命令的话,会看到tcp、udp的字样,解释如下。
Tcp
udp
至于计算机的网络,简单了解下这个过程。
机器得有网卡、得插网线(物理层)
↓
机器上的网络适配器能拿到ip地址
↓
计算机之间可以基于ip地址,进行数据交互
(基于tcp协议的数据交互,李文杰想给于超老师发一个小电影,两个人一拍即合,满心欢喜,握手言和,达成一致目的)
(基于udp协议的数据交互,李文杰不管超哥爱不爱看小电影,反正一顿发数据,直到把超哥的机器占满网络带宽,卡死)
↓
丰富的应用层协议(如网站服务的HTTP协议)
tcp/udp
TCP(传输控制协议)和UDP(用户数据报协议)是两种常见的传输层协议,用于在计算机网络中传输数据。它们在功能和特性上有很大的区别,适用于不同的应用场景。
- TCP(传输控制协议):
- 特点:面向连接、可靠传输、有序传输、重传机制、流量控制、拥塞控制。
- 适用场景:适用于要求数据可靠传输、顺序到达、不允许丢包和重复的应用,如文件传输、网页浏览、邮件传输等。
- 优点:保证数据传输的可靠性和顺序性,适用于对数据完整性要求较高的应用。
- 缺点:由于重传和流量控制机制,可能会引入较大的延迟和网络开销。
- UDP(用户数据报协议):
- 特点:无连接、不可靠传输、无序传输、不提供拥塞控制和流量控制。
- 适用场景:适用于实时性要求高、数据丢失可以容忍的应用,如视频流、音频通话、在线游戏等。
- 优点:传输速度快,适用于对实时性要求较高的应用。
- 缺点:不保证数据传输的可靠性和顺序性,可能会丢失数据包。
总的来说,TCP 适用于对数据可靠性要求高的应用,而 UDP 适用于对实时性要求高、对数据可靠性要求不那么严格的应用。在实际应用中,根据具体的需求和场景选择合适的协议非常重要。
理解linux网络,ip和socket,以及如何运维
ccna ccnp 网络协议课程
在 Linux 中,网络是指计算机之间通过网络连接进行通信和数据交换的能力。Linux 提供了丰富的网络功能和工具,使其成为构建网络应用和进行网络管理的理想平台。以下是关于 Linux 网络、IP、Socket 的基本概念以及如何进行运维的一些信息:
- Linux 网络:Linux 提供了完整的网络协议栈,包括物理层、数据链路层、网络层、传输层和应用层。它支持各种网络协议,如 TCP/IP、UDP、ICMP、HTTP 等,以实现不同类型的网络通信和应用。
- IP(Internet Protocol):IP 是 Internet 上的主要网络协议之一,用于在网络上唯一标识和定位设备。在 Linux 中,可以使用
ifconfig或ip命令来管理网络接口和配置 IP 地址。 - Socket:Socket 是在网络中进行通信的一种机制,它允许不同主机上的应用程序通过网络进行数据交换。在 Linux 中,Socket 被用于实现网络通信,可以通过编程接口(如 POSIX Socket API)创建和管理 Socket。
- 网络运维:在 Linux 中进行网络运维包括以下方面:
- 配置网络接口:使用工具如
ifconfig、ip或编辑配置文件来配置网络接口。 - 管理路由:使用
route或ip route命令管理网络路由表,以确定数据包的传输路径。 - 防火墙配置:使用
iptables或其他防火墙工具配置防火墙规则,保护网络安全。 - 监控网络状态:使用工具如
netstat、ss、nload、iftop等来监控网络连接和流量。 - 故障排除:使用工具和技术来诊断和解决网络问题,如使用
ping、traceroute来检查网络连通性,使用日志来分析网络问题等。
- 配置网络接口:使用工具如
通过理解 Linux 网络、IP、Socket 的基本概念,并掌握相关的运维技能,可以帮助管理员更好地管理和维护 Linux 系统的网络功能,确保网络的稳定性和安全性。
ss详解
ss 命令是一个强大的工具,用于查看套接字(socket)统计信息。它可以显示各种网络套接字的状态,包括 TCP、UDP、RAW 和 UNIX 套接字。下面是 ss 命令的一些常用选项和功能:
-t:显示 TCP 套接字。-u:显示 UDP 套接字。-l:显示监听状态的套接字。-a:显示所有套接字。-n:以数字形式显示地址和端口号。-p:显示与套接字关联的进程信息。-s:显示套接字统计信息。-H:显示标题行。-h:显示帮助信息。
ss 命令的常见用法包括查看网络连接、过滤特定状态的连接、显示进程信息等。以下是一些常见用法:
显示所有套接字信息:
ss -a这将显示所有类型(TCP、UDP、RAW 和 UNIX)的套接字信息。
显示 TCP 套接字信息:
ss -t这将显示所有 TCP 套接字的信息。
显示监听状态的套接字信息:
ss -l这将显示所有处于监听状态的套接字信息。
显示 UDP 套接字信息:
ss -u这将显示所有 UDP 套接字的信息。
显示进程信息:
ss -p这将显示与套接字关联的进程信息。
显示套接字统计信息:
ss -s这将显示套接字的统计信息,包括各种套接字的数量。
显示特定端口的套接字信息:
ss -t -a 'sport = :80'这将显示本地端口为 80 的 TCP 套接字信息。
显示特定状态的套接字信息:
ss -a state TIME-WAIT这将显示所有处于 TIME-WAIT 状态的套接字信息。
显示 IPv4 和 IPv6 套接字信息:
ss -t -6这将显示 IPv6 的 TCP 套接字信息。
显示详细信息:
ss -t -i这将显示详细的套接字信息,包括 TCP 连接的详细状态。
请注意,ss 命令的选项和用法可能会根据不同的操作系统版本和发行版而有所不同。建议查阅相应操作系统的文档或使用 man ss 命令查看完整的 ss 命令文档。
netstat和ss区别
ss 命令和 netstat 命令都用于显示网络套接字信息,但它们之间有一些区别:
- 性能:
ss命令在性能上比netstat更好,因为它使用了更有效的内核接口来获取套接字信息。在高负载系统上,ss命令的响应速度更快。netstat命令在某些情况下可能会导致性能问题,特别是在连接数较多的情况下。
- 功能:
ss命令提供的功能比netstat更丰富,例如可以显示更多类型的套接字(如 RAW 和 UNIX 套接字)、更多的过滤选项和状态等。netstat命令在某些情况下可能更容易使用,因为它的输出格式可能更直观。
- 支持:
ss命令通常在较新的 Linux 系统上可用,而netstat命令则在几乎所有的 UNIX 和类 UNIX 系统上都可用,包括 Linux、BSD 和 macOS 等。
综上所述,ss 命令在性能和功能上都优于 netstat 命令,特别是在需要处理大量连接的系统上。因此,在新的 Linux 系统上推荐使用 ss 命令来替代 netstat。
流量监控
Ubuntu上有几种方法可以监控流量。以下是其中一些常用的方法:
使用iftop: iftop是一个实时网络流量监控工具,可以在终端中显示网络流量的实时统计信息。您可以使用以下命令安装iftop:
sudo apt install iftop然后,使用以下命令运行iftop:
sudo iftop按下
h键查看iftop的帮助信息,了解如何使用它。使用nload: nload也是一个终端网络流量监控工具,可以显示网络接口的实时流量统计信息。您可以使用以下命令安装nload:
sudo apt install nload然后,使用以下命令运行nload:
sudo nload使用vnstat: vnstat是一个网络流量监控工具,可以记录并显示网络接口的流量使用情况。您可以使用以下命令安装vnstat:
sudo apt install vnstat安装后,您可以使用以下命令查看流量统计信息:
vnstat或者,您也可以使用
vnstat -l命令查看实时流量信息。
这些工具都可以帮助您监控Ubuntu系统上的网络流量。您可以根据自己的需求选择适合的工具。
iftop命令
iftop是一个用于实时监控网络流量的命令行工具。以下是一些常用的iftop运维命令:
- 启动iftop:直接在终端中运行
sudo iftop命令即可启动iftop。默认情况下,iftop将显示所有网络接口的流量信息。您可以使用-i参数指定要监控的特定网络接口,例如sudo iftop -i eth0。 - 显示帮助信息:按下
h键可以查看iftop的帮助信息,其中包含了可用的命令选项和快捷键。 - 切换显示单位:分别按下
n键大写,小写,切换域名,端口的dns解析。 - 暂停/继续显示:按下
P键可以暂停或继续显示流量信息。 - 显示端口:按下小写p键,开启,关闭端口号。
- 切换显示方向:按下
t键可以在传入流量和传出流量之间切换显示。 - 设置显示过滤器:按下
L键可以设置过滤器,以仅显示符合条件的流量。例如,可以按源或目标IP地址过滤流量。 - 退出iftop:按下
q键可以退出iftop。
这些是一些常用的iftop运维命令,可以帮助您更好地使用iftop进行网络流量监控。